Apache Flink
Apache Flink Documentation (1.20)
Stateful Stream Processing: Concepts, Tools, & Challenges
Batch Processing vs Stream Processing: Pros, Cons, Examples
What is Flink
Like Apache Hadoop and Apache Spark, Apache Flink is a community-driven open source framework for distributed Big Data Analytics. Written in Java, Flink has APIs for Scala, Java and Python, allowing for Batch and Real-Time streaming analytics.
Requirements
- UNIX-like environment, such as Linux, Mac OS X or Cygwin
- Java 6+
- [optional] Maven 3.0.4+
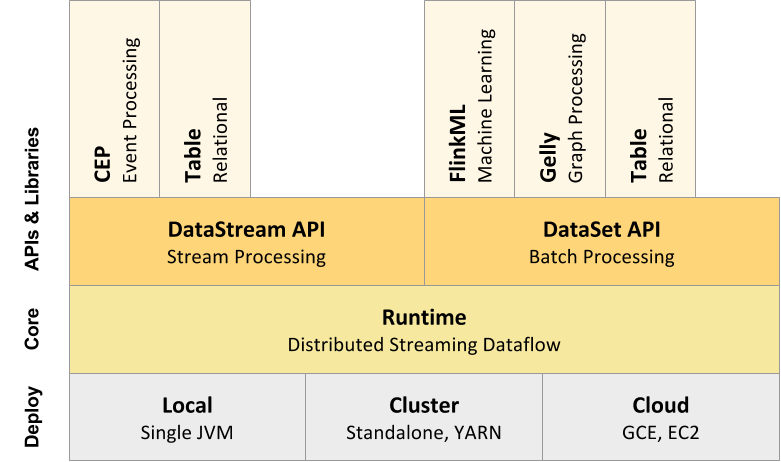
Stack
Stream Processing
When you analyze data, you can either organize your processing around bounded or unbounded stream.
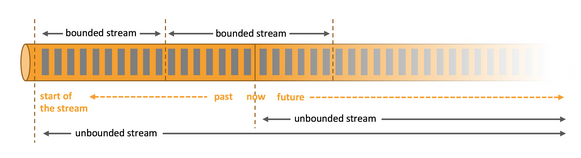
Batch processing is the paradigm at work when you process a bounded data stream. In this mode of operation you can choose to ingest the entire dataset before producing any results, which means that it is possible, for example, to sort the data, compute global statistics, or produce a final report that summarizes all of the input.
Stream processing, on the other hand, involves unbounded data streams. Conceptually, at least, the input may never end, and so you are forced to continuously process the data as it arrives.
JobManager & TaskManagers
- JobManager coordinates the distributed execution of Flink Applications. It decides when to schedule the next task or set of tasks. It reacts to completed tasks and task failures, coordinates checkpoints, coordinates recovery from failures and more.
- TaskManagers (also called workers) execute the tasks of a dataflow, and buffer and exchange the data streams. There must always be at least one TaskManager. The smallest unit of resource scheduling in a TaskManager is a task slot. The number of task slots in a TaskManager indicates the number of concurrent processing tasks. Note that multiple operators may execute in a task slot. Each TaskManager is a JVM process.
Flink Application
A Flink Application is any user program that spawns one or multiple Flink jobs from its main() method. The execution of these jobs can happen in a local JVM (LocalEnvironment) or on a remote setup of clusters with multiple machines (RemoteEnvironment). For each program, the ExecutionEnvironment provides methods to control the job execution and to interact with the outside world.
The jobs of a Flink Application can either be submitted to a long-running Flink Session Cluster, a dedicated cluster, or a Flink Application Cluster. Confluent Platform for Apache Flink supports Flink Application Clusters.
Flink APIs
- SQL provides the highest level of abstraction for Flink. This abstraction is similar to the Table API both in semantics and expressiveness, but represents programs as SQL query expressions. The Flink SQL abstraction interacts with the Table API, and SQL queries can be executed over tables defined in the Table API.
- Table API is a declarative DSL centered around tables, which may be dynamically changing tables (when representing streams). The Table API follows the (extended) relational model: Tables have a schema attached, similar to tables in relational databases, and the Table API provides comparable operations, such as select, project, join, group-by, aggregate, and more. Table API programs declaratively define what logical operation should be done rather than specifying exactly how the code for the operation looks. Though the Table API is extensible by various types of user-defined functions, it is less expressive than the Core APIs, and more concise to use, meaning you write less code. In addition, Table API programs go through an optimizer that applies optimization rules before execution. You can seamlessly convert between tables and DataStream APIs enabling programs to mix the Table API with the DataStream API.
- DataStream API offers the common building blocks for data processing, like various forms of user-specified transformations, joins, aggregations, windows, state, etc. Data types processed in DataStream API are represented as classes in the respective programming languages. In addition, you can also use the lower-level Process Function operation with the DataStream API, so it is possible to use the lower-level abstraction when necessary.
- The lowest level of abstraction offers stateful and timely stream processing with the Process Function operator. The ProcessFunction operator, which is embedded in DataStream API enables users to freely process events from one or more streams, and provides consistent, fault tolerant state. In addition, users can register event time and processing time callbacks, allowing programs to realize sophisticated computations. In practice, many applications don’t need the low-level abstractions offered by the Process Function operation, and can instead use the DataStream API for bounded and unbounded streams.
- The DataSet API has been deprecated.
- Parallel dataflows
- Timely stream processing
- Stateful stream processing
- State management
Basic Flink Program Structure
1. Execution Environment
The execution environment is where your program will run. Flink provides different execution environments based on the context, such as local, remote, or a cluster environment. The environment serves as the entry point for all Flink applications.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
2. Data Sources
Data sources define where your input data is coming from. Flink can read data from various sources such as files, Kafka topics, sockets, and more.
- Apache Kafka: For reading from Kafka topics.
- Kinesis: For reading from AWS Kinesis streams.
- RabbitMQ: For reading from RabbitMQ queues.
- Files: For reading from various file formats (CSV, JSON, Avro).
- Socket: For reading from socket streams.
- JDBC: For reading from relational databases.
- Cassandra: For reading data from Apache Cassandra tables, A NoSQL DBMS
DataStream<String> text = env.readTextFile("path/to/your/file");
3. Transformations
Transformations are operations that process and modify the data. Flink provides a rich set of transformation operations such as map, flatMap, filter, keyBy, and more.
DataStream<Tuple2<String, Integer>> wordCounts = text
.flatMap(new Tokenizer())
.keyBy(tuple -> tuple.f0)
.sum(1);
4. Sinks
Sinks define where the processed data should be written to. Common sinks include files, databases, and standard output.
- Apache Kafka: For writing to Kafka topics.
- Kinesis: For writing to AWS Kinesis streams.
- Elasticsearch: For writing to Elasticsearch indexes.
- Files: For writing to various file formats (CSV, JSON, Avro).
- JDBC: For writing to relational databases.
- HDFS: For writing to Hadoop Distributed File System.
- Cassandra: For writing to Apache Cassandra tables.
wordCounts.print();
5. Windowing
Windowing groups data into time-based or count-based windows for aggregation.
DataStream<Tuple2<String, Integer>> windowedCounts = stream
.flatMap(new Tokenizer())
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.sum(1);
6. Execute the Program
The execution of the Flink program is triggered by calling the execute method on the StreamExecutionEnvironment. This method compiles the program into a dataflow graph and sends it for execution.
env.execute("Flink WordCount Example");
7. DataStream Connectors
- Apache Kafka (source/sink)
- Apache Cassandra (source/sink)
- Amazon DynamoDB (sink)
- Amazon Kinesis Data Streams (source/sink)
- Amazon Kinesis Data Firehose (sink)
- DataGen (source)
- Elasticsearch (sink)
- Opensearch (sink)
- FileSystem (source/sink)
- RabbitMQ (source/sink)
- Google PubSub (source/sink)
- Hybrid Source (source)
- Apache Pulsar (source)
- JDBC (sink)
- MongoDB (source/sink)
🗃️ DataStream API
2 items
🗃️ Table API & SQL
3 items
🗃️ Operators
2 items
🗃️ Connectors
2 items
📄️ Flink ML (machine learning)
Machine Learning
🗃️ Examples
12 items
📄️ References
Apache Flink