Apache Hadoop
Apache Hadoop
https://www.tpointtech.com/hadoop-tutorial
Apache’s Hadoop is a leading Big Data platform used by IT giants Yahoo, Facebook & Google.
Apache Hadoop is an open source software framework used to develop data processing applications which are executed in a distributed computing environment. (A distributed system is simply any environment where multiple computers or devices are working on a variety of tasks and components, all spread across a network. Components within distributed systems split up the work, coordinating efforts to complete a given job more efficiently than if only a single device ran it.)
Similar to data residing in a local file system of a personal computer system, in Hadoop, data resides in a distributed file system which is called as a Hadoop Distributed File System (HDFS). The processing model is based on ‘Data Locality’ concept wherein computational logic is sent to cluster nodes (servers) containing data. This computational logic is nothing, but a compiled version of a program written in a high-level language such as Java. Such a program, processes data stored in Hadoop HDFS.
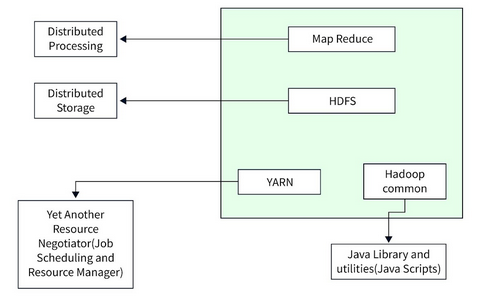
The Hadoop Architecture Mainly consists of 4 components.
- MapReduce: This is a framework which helps Java programs to do the parallel computation on data using key value pair. The Map task takes input data and converts it into a data set which can be computed in Key value pair. The output of Map task is consumed by Reduce task and then the out of reducer gives the desired result.
- HDFS (Hadoop Distributed File System): It states that the files will be broken into blocks and stored in nodes over the distributed architecture.
- YARN (Yet Another Resource Negotiator): Yet another Resource Negotiator is used for job scheduling and manage the cluster.
- Common Utilities or Hadoop Common: These Java libraries are used to start Hadoop and are used by other Hadoop modules.
MapReduce
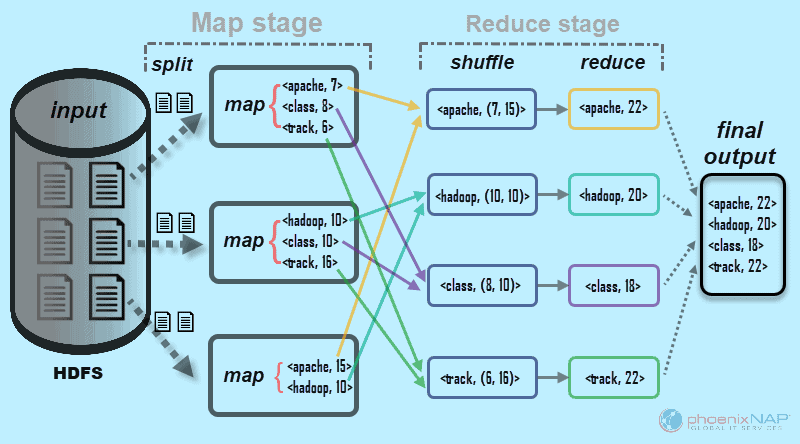
A MapReduce system is usually composed of three steps (even though it's generalized as the combination of Map and Reduce operations/functions). The MapReduce operations are:
- Map: The input data is first split into smaller blocks. The Hadoop framework then decides how many mappers to use, based on the size of the data to be processed and the memory block available on each mapper server. Each block is then assigned to a mapper for processing. Each ‘worker’ node applies the map function to the local data, and writes the output to temporary storage. The primary (master) node ensures that only a single copy of the redundant input data is processed.
- Shuffle, combine and partition: worker nodes redistribute data based on the output keys (produced by the map function), such that all data belonging to one key is located on the same worker node. As an optional process the combiner (a reducer) can run individually on each mapper server to reduce the data on each mapper even further making reducing the data footprint and shuffling and sorting easier. Partition (not optional) is the process that decides how the data has to be presented to the reducer and also assigns it to a particular reducer.
- Reduce: A reducer cannot start while a mapper is still in progress. Worker nodes process each group of
<key,value>pairs output data, in parallel to produce<key,value>pairs as output. All the map output values that have the same key are assigned to a single reducer, which then aggregates the values for that key. Unlike the map function which is mandatory to filter and sort the initial data, the reduce function is optional.
HDFS (Hadoop Distributed File System)
More detailed description: HDFS Tutorial
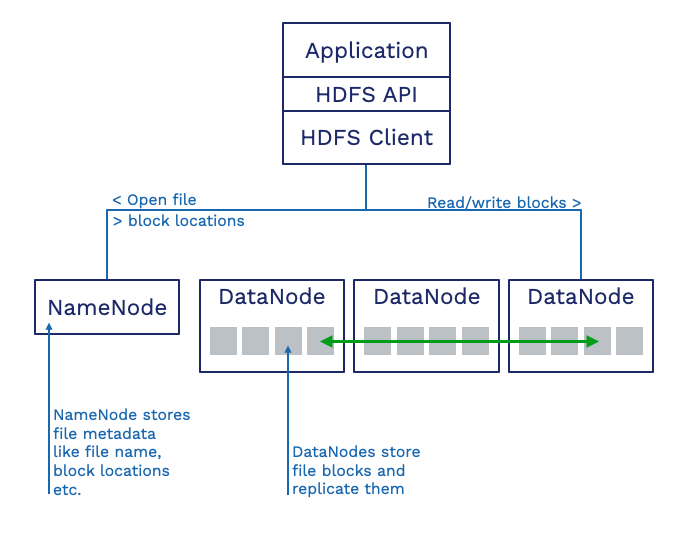
HDFS has three components:
- NameNode: There is a single NameNode per cluster. This service stores the file system metadata (e.g., the directory structure), and the file names, and also, the location where the blocks of a file are stored.
- DataNodes: These services usually run on each server that also does the compute. Each DataNode stores blocks from many files. The DataNodes are also responsible for replicating these blocks to other DataNodes to protect files against data loss.
- Clients: The client provides access to the file system and the Hadoop/MapReduce jobs that want to access the data. The client, a piece of software embedded in the Hadoop distribution, communicates with the NameNode to find the file and retrieve the block’s locations. Then the client reads or writes the blocks directly from the DataNodes.
Read Operation In HDFS
Read / Write Operations in HDFS
Data read request is served by HDFS, NameNode, and DataNode. Let’s call the reader as a ‘client’. Below diagram depicts file read operation in Hadoop.
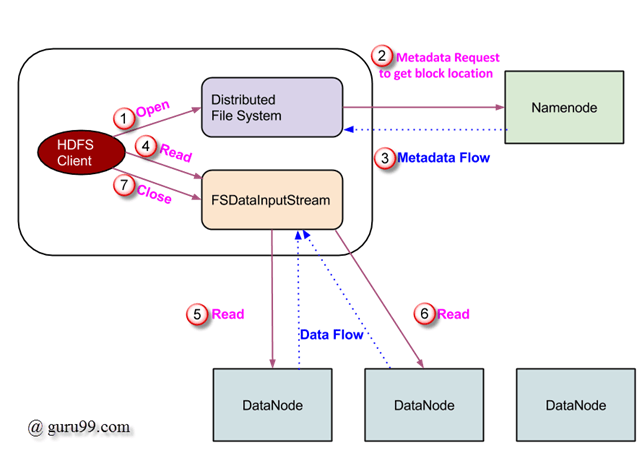
- A client initiates read request by calling ‘open()’ method of FileSystem object; it is an object of type DistributedFileSystem.
- This object connects to namenode using RPC and gets metadata information such as the locations of the blocks of the file. Please note that these addresses are of first few blocks of a file.
- In response to this metadata request, addresses of the DataNodes having a copy of that block is returned back.
- Once addresses of DataNodes are received, an object of type FSDataInputStream is returned to the client. FSDataInputStream contains DFSInputStream which takes care of interactions with DataNode and NameNode. In step 4 shown in the above diagram, a client invokes ‘read()’ method which causes DFSInputStream to establish a connection with the first DataNode with the first block of a file.
- Data is read in the form of streams wherein client invokes ‘read()’ method repeatedly. This process of read() operation continues till it reaches the end of block.
- Once the end of a block is reached, DFSInputStream closes the connection and moves on to locate the next DataNode for the next block
- Once a client has done with the reading, it calls a close() method.
Write Operation In HDFS
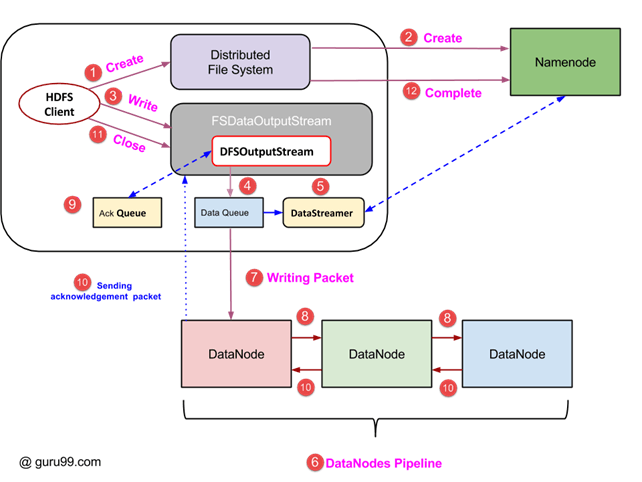
- A client initiates write operation by calling ‘create()’ method of DistributedFileSystem object which creates a new file – Step no. 1 in the above diagram.
- DistributedFileSystem object connects to the NameNode using RPC call and initiates new file creation. However, this file creates operation does not associate any blocks with the file. It is the responsibility of NameNode to verify that the file (which is being created) does not exist already and a client has correct permissions to create a new file. If a file already exists or client does not have sufficient permission to create a new file, then IOException is thrown to the client. Otherwise, the operation succeeds and a new record for the file is created by the NameNode.
- Once a new record in NameNode is created, an object of type FSDataOutputStream is returned to the client. A client uses it to write data into the HDFS. Data write method is invoked (step 3 in the diagram).
- FSDataOutputStream contains DFSOutputStream object which looks after communication with DataNodes and NameNode. While the client continues writing data, DFSOutputStream continues creating packets with this data. These packets are enqueued into a queue which is called as DataQueue.
- There is one more component called DataStreamer which consumes this DataQueue. DataStreamer also asks NameNode for allocation of new blocks thereby picking desirable DataNodes to be used for replication.
- Now, the process of replication starts by creating a pipeline using DataNodes. In our case, we have chosen a replication level of 3 and hence there are 3 DataNodes in the pipeline.
- The DataStreamer pours packets into the first DataNode in the pipeline.
- Every DataNode in a pipeline stores packet received by it and forwards the same to the second DataNode in a pipeline.
- Another queue, ‘Ack Queue’ is maintained by DFSOutputStream to store packets which are waiting for acknowledgment from DataNodes.
- Once acknowledgment for a packet in the queue is received from all DataNodes in the pipeline, it is removed from the ‘Ack Queue’. In the event of any DataNode failure, packets from this queue are used to reinitiate the operation.
- After a client is done with the writing data, it calls a close() method (Step 9 in the diagram) Call to close(), results into flushing remaining data packets to the pipeline followed by waiting for acknowledgment.
- Once a final acknowledgment is received, NameNode is contacted to tell it that the file write operation is complete.
YARN (Yet Another Resource Negotiator)
YARN is a Framework on which MapReduce works. YARN performs 2 operations that are Job scheduling and Resource Management. The Purpose of Job schedular is to divide a big task into small jobs so that each job can be assigned to various slaves in a Hadoop cluster and Processing can be Maximized. Job Scheduler also keeps track of which job is important, which job has more priority, dependencies between the jobs and all the other information like job timing, etc. And the use of Resource Manager is to manage all the resources that are made available for running a Hadoop cluster.
Features of YARN
- Multi-Tenancy
- Scalability
- Cluster-Utilization
- Compatibility
Hadoop Common Utilities
Hadoop common or Common utilities are nothing but our java library and java files or we can say the java scripts that we need for all the other components present in a Hadoop cluster. these utilities are used by HDFS, YARN, and MapReduce for running the cluster. Hadoop Common verify that Hardware failure in a Hadoop cluster is common so it needs to be solved automatically in software by Hadoop Framework.
Network Topology In Hadoop
Topology (Arrangement) of the network, affects the performance of the Hadoop cluster when the size of the Hadoop cluster grows. In addition to the performance, one also needs to care about the high availability and handling of failures. In order to achieve this Hadoop, cluster formation makes use of network topology.

Typically, network bandwidth is an important factor to consider while forming any network. However, as measuring bandwidth could be difficult, in Hadoop, a network is represented as a tree and distance between nodes of this tree (number of hops) is considered as an important factor in the formation of Hadoop cluster. Here, the distance between two nodes is equal to sum of their distance to their closest common ancestor.
Hadoop cluster consists of a data center, the rack and the node which actually executes jobs. Here, data center consists of racks and rack consists of nodes. Network bandwidth available to processes varies depending upon the location of the processes. That is, the bandwidth available becomes lesser as we go away from-
- Processes on the same node
- Different nodes on the same rack
- Nodes on different racks of the same data center
- Nodes in different data centers
📄️ Setting up a Single Node Cluster
How to Install Hadoop on Ubuntu
📄️ SQOOP
Apache Sqoop
📄️ HBase
https://hbase.apache.org/
📄️ HBase in Pseudo-Distributed Mode with Kerberos Authentication
Prerequisites
📄️ Hadoop-3.2.1 using Docker 01
Description
📄️ Hadoop-3.4.1 using Docker 02
Description
🗃️ Hive
1 item
🗃️ Examples
7 items
📄️ References
Hadoop & Mapreduce Examples: Create First Program in Java