HBase
https://hbase.apache.org/
https://hbase.apache.org/book.html
https://hbase.apache.org/book.html#quickstart_pseudo
https://www.tutorialspoint.com/hbase/hbase_overview.htm
https://www.cloudduggu.com/hbase/introduction/
https://www.edureka.co/blog/hbase-architecture/
https://nag-9-s.gitbook.io/hbase/hbase-architecture
Apache Hbase Security with Kerberos | Complete Guide
Enabling Servers for Pseudo-distributed Operation
Apache HBase is an open-source, NoSQL, distributed big data store. It enables random, strictly consistent, real-time access to petabytes of data. HBase is very effective for handling large, sparse datasets. HBase is a data model that is similar to Google’s big table. It is an open source, distributed database developed by Apache software foundation written in Java. HBase is an essential part of our Hadoop ecosystem. HBase runs on top of HDFS (Hadoop Distributed File System). It can store massive amounts of data from terabytes to petabytes. It is column oriented and horizontally scalable.
Applications of Apache HBase:
Real-time analytics: HBase is an excellent choice for real-time analytics applications that require low-latency data access. It provides fast read and write performance and can handle large amounts of data, making it suitable for real-time data analysis.
Social media applications: HBase is an ideal database for social media applications that require high scalability and performance. It can handle the large volume of data generated by social media platforms and provide real-time analytics capabilities.
IoT applications: HBase can be used for Internet of Things (IoT) applications that require storing and processing large volumes of sensor data. HBase’s scalable architecture and fast write performance make it a suitable choice for IoT applications that require low-latency data processing.
Online transaction processing: HBase can be used as an online transaction processing (OLTP) database, providing high availability, consistency, and low-latency data access. HBase’s distributed architecture and automatic failover capabilities make it a good fit for OLTP applications that require high availability.
Ad serving and clickstream analysis: HBase can be used to store and process large volumes of clickstream data for ad serving and clickstream analysis. HBase’s column-oriented data storage and indexing capabilities make it a good fit for these types of applications.
Features of HBase –
- It is linearly scalable across various nodes as well as modularly scalable, as it divided across various nodes.
- HBase provides consistent read and writes.
- It provides atomic read and write means during one read or write process, all other processes are prevented from performing any read or write operations.
- It provides easy to use Java API for client access.
- It supports Thrift and REST API for non-Java front ends which supports XML, Protobuf and binary data encoding options.
- It supports a Block Cache and Bloom Filters for real-time queries and for high volume query optimization.
- HBase provides automatic failure support between Region Servers.
- It support for exporting metrics with the Hadoop metrics subsystem to files.
- It doesn’t enforce relationship within your data.
- It is a platform for storing and retrieving data with random access.
Advantages Of Apache HBase:
- Scalability: HBase can handle extremely large datasets that can be distributed across a cluster of machines. It is designed to scale horizontally by adding more nodes to the cluster, which allows it to handle increasingly larger amounts of data.
- High-performance: HBase is optimized for low-latency, high-throughput access to data. It uses a distributed architecture that allows it to process large amounts of data in parallel, which can result in faster query response times.
- Flexible data model: HBase’s column-oriented data model allows for flexible schema design and supports sparse datasets. This can make it easier to work with data that has a variable or evolving schema.
- Fault tolerance: HBase is designed to be fault-tolerant by replicating data across multiple nodes in the cluster. This helps ensure that data is not lost in the event of a hardware or network failure.
Disadvantages Of Apache HBase:
- Complexity: HBase can be complex to set up and manage. It requires knowledge of the Hadoop ecosystem and distributed systems concepts, which can be a steep learning curve for some users.
- Limited query language: HBase’s query language, HBase Shell, is not as feature-rich as SQL. This can make it difficult to perform complex queries and analyses. -No support for transactions: HBase does not support transactions, which can make it difficult to maintain data consistency in some use cases.
- Not suitable for all use cases: HBase is best suited for use cases where high throughput and low-latency access to large datasets is required. It may not be the best choice for applications that require real-time processing or strong consistency guarantees.
HBase and HDFS
In most cases, HBase stores its data in Apache HDFS. This includes the HFiles containing the data, as well as the write-ahead logs (WALs) which store data before it is written to the HFiles and protect against RegionServer crashes. HDFS provides reliability and protection to data in HBase because it is distributed. To operate with the most efficiency, HBase needs data to be available locally. Therefore, it is a good practice to run an HDFS DataNode on each RegionServer.

HBase Data Model
HBase is a column-oriented NoSQL database. Although it looks similar to a relational database which contains rows and columns, but it is not a relational database. Relational databases are row oriented while HBase is column-oriented.
Column-Oriented Databases
- When the amount of data is very huge, like in terms of petabytes or exabytes, we use column-oriented approach, because the data of a single column is stored together and can be accessed faster.
- While row-oriented approach comparatively handles less number of rows and columns efficiently, as row-oriented database stores data is a structured format.
- When we need to process and analyze a large set of semi-structured or unstructured data, we use column oriented approach. Such as applications dealing with Online Analytical Processing like data mining, data warehousing, applications including analytics, etc.
- Whereas, Online Transactional Processing such as banking and finance domains which handle structured data and require transactional properties (ACID properties) use row-oriented approach.
HBase tables has following components, shown in the image below:
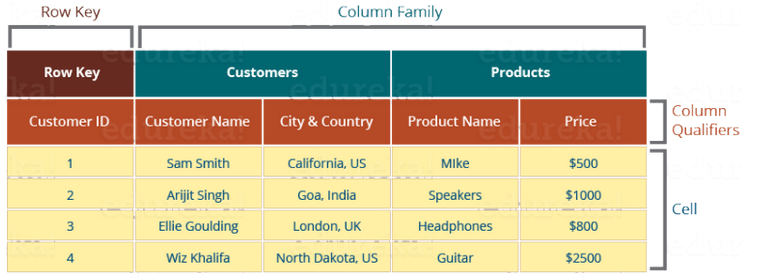
Table Example
hbase:001:0> scan 'customers-100':
hbase:001:0> scan 'customers-100'
ROW COLUMN+CELL
1 column=City:, timestamp=2025-03-22T16:08:00.164, value=East Leonard
1 column=Company:, timestamp=2025-03-22T16:08:00.164, value=Rasmussen Group
1 column=Country:, timestamp=2025-03-22T16:08:00.164, value=Chile
1 column=Customer_Id:, timestamp=2025-03-22T16:08:00.164, value=DD37Cf93aecA6Dc
1 column=Email:, timestamp=2025-03-22T16:08:00.164, value=zunigavanessa@smith.info
1 column=First_Name:, timestamp=2025-03-22T16:08:00.164, value=Sheryl
1 column=Last_Name:, timestamp=2025-03-22T16:08:00.164, value=Baxter
1 column=Phone_1:, timestamp=2025-03-22T16:08:00.164, value=229.077.5154
1 column=Phone_2:, timestamp=2025-03-22T16:08:00.164, value=397.884.0519x718
1 column=Subscription_Date:, timestamp=2025-03-22T16:08:00.164, value=2020-08-24
1 column=Website:, timestamp=2025-03-22T16:08:00.164, value=http://www.stephenson.com/
10 column=City:, timestamp=2025-03-22T16:08:00.164, value=Elaineberg
10 column=Company:, timestamp=2025-03-22T16:08:00.164, value=Beck-Hendrix
10 column=Country:, timestamp=2025-03-22T16:08:00.164, value=Timor-Leste
...
...
HBase Components
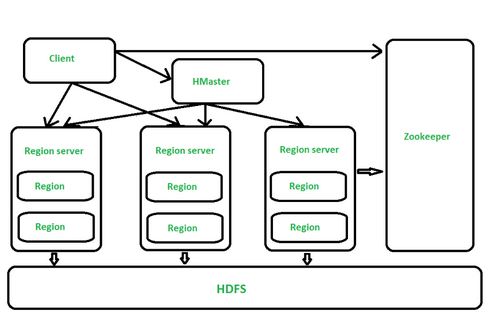
- HMaster
The implementation of Master Server in HBase is HMaster. It is a process in which regions are assigned to region server as well as DDL (create, delete table) operations. It monitor all Region Server instances present in the cluster. In a distributed environment, Master runs several background threads. HMaster has many features like controlling load balancing, failover etc.
- Region Server
- Regions - HBase Tables are divided horizontally by row key range into “Regions.”
- A region contains all rows in the table between the region’s start key and end key.
- Regions are assigned to the nodes in the cluster, called “Region Servers,” and these serve data for reads and writes.
- A region server can serve about 1,000 regions.
- Each region is 1GB in size (default)
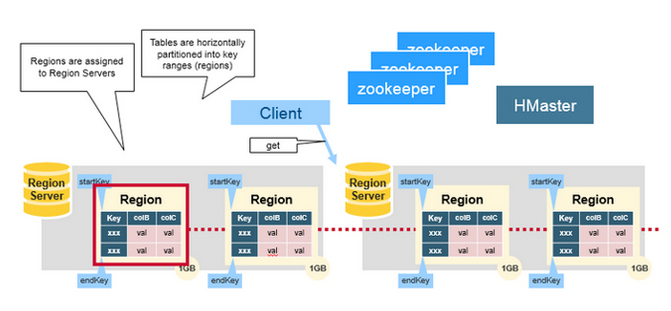
- The basic unit of scalability and load balancing in HBase is called a region. These are essentially contiguous ranges of rows stored together. They are dynamically split by the system when they become too large. Alternatively, they may also be merged to reduce their number and required storage files. An HBase system ma y have more than one region servers.
- Initially there is only one region for a table and as we start adding data to it, the system is monitoring to ensure that you do not exceed a configured maximum size. If you exceed the limit, the region is split into two at the middle key middle of the region, creating two roughly equal halves.
- Each region is served by exactly one region server, the row key in the and each of these servers can serve many regions at any time.
- Rows are grouped in regions and may be served by different servers
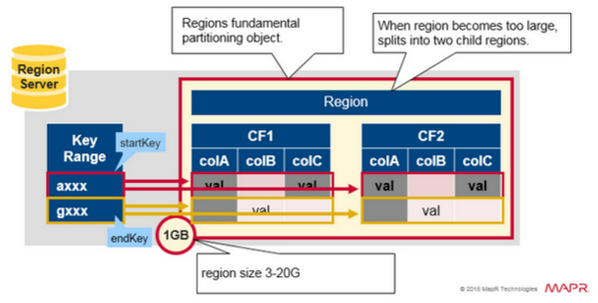
- HFile - HFile represents the real data storage file. The files contain a variable number of data blocks and a fixed number of file info blocks and trailer blocks.
- WAL(HLog) -
- In the case of writing the data, when the client calls HTable.put(Put), the data is frst written to the write-ahead log fle (which contains actual data and sequence numbers together represented by the HLogKey class) and also written in MemStore.
- Writing data directly into MemStrore can be dangerous as it is a volatile in-memory buffer and always open to the risk of losing data in case of a server failure.
- Once MemStore is full, the contents of the MemStore are flushed to the disk by creating a new HFile on the HDFS.
- If there is a server failure, the WAL can effectively retrieve the log to get everything up to where the server was prior to the crash failure. Hence, the WAL guarantees that the data is never lost.
- Also, as another level of assurance, the actual write-ahead log resides on the HDFS, which is a replicated filesystem. Any other server having a replicated copy can open the log.
- The HLog class represents the WAL. When an HRegion object is instantiated, the single HLog instance is passed on as a parameter to the constructor of HRegion. In the case of an update operation, it saves the data directly to the shared WAL and also keeps track of the changes by incrementing the sequence numbers for each edit.
- WAL uses a Hadoop SequenceFile, which stores records as sets of key-value pairs.
- Here, the HLogKey instance represents the key, and the key-value represents the rowkey, column family, column qualifier, timestamp, type, and value along with the region and table name where data needs to be stored.
- Also, the structure starts with two fixed-length numbers that indicate the size and value of the key.
- Zookeeper
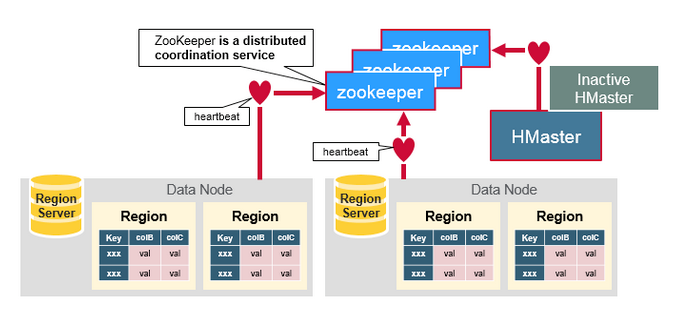
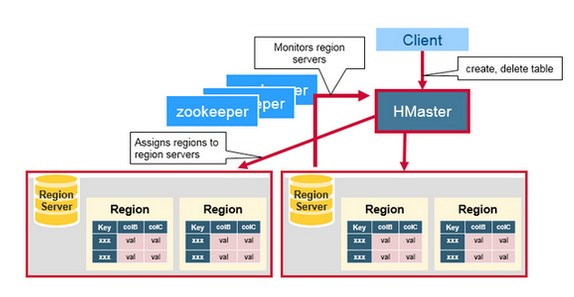
- Zookeeper acts like a coordinator inside HBase distributed environment. It helps in maintaining server state inside the cluster by communicating through sessions.
- Every Region Server along with HMaster Server sends continuous heartbeat at regular interval to Zookeeper and it checks which server is alive and available as mentioned in above image. It also provides server failure notifications so that, recovery measures can be executed.
- Referring from the above image you can see, there is an inactive server, which acts as a backup for active server. If the active server fails, it comes for the rescue.
- The active HMaster sends heartbeats to the Zookeeper while the inactive HMaster listens for the notification send by active HMaster. If the active HMaster fails to send a heartbeat the session is deleted and the inactive HMaster becomes active.
- While if a Region Server fails to send a heartbeat, the session is expired and all listeners are notified about it. Then HMaster performs suitable recovery actions which we will discuss later in this blog.
- Zookeeper also maintains the .META Server’s path, which helps any client in searching for any region. The Client first has to check with .META Server in which Region Server a region belongs, and it gets the path of that Region Server.
- How the Components Work Together
Zookeeper is used to coordinate shared state information for members of distributed systems. Region servers and the active HMaster connect with a session to ZooKeeper. The ZooKeeper maintains ephemeral nodes for active sessions via heartbeats.
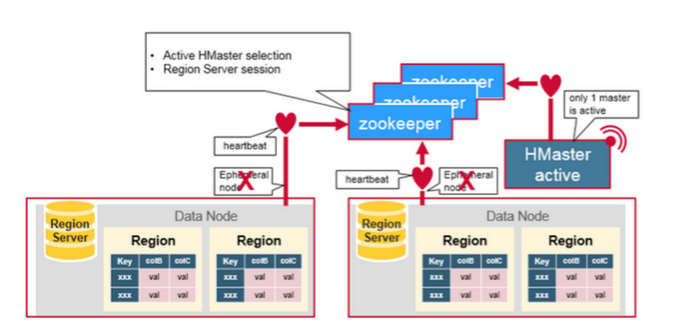
Each Region Server creates an ephemeral node. The HMaster monitors these nodes to discover available region servers, and it also monitors these nodes for server failures. HMasters vie to create an ephemeral node. Zookeeper determines the first one and uses it to make sure that only one master is active. The active HMaster sends heartbeats to Zookeeper, and the inactive HMaster listens for notifications of the active HMaster failure.
If a region server or the active HMaster fails to send a heartbeat, the session is expired and the corresponding ephemeral node is deleted. Listeners for updates will be notified of the deleted nodes. The active HMaster listens for region servers, and will recover region servers on failure. The Inactive HMaster listens for active HMaster failure, and if an active HMaster fails, the inactive HMaster becomes active.
Install HBase
su - hadoop
/home/hadoop:
Download and untar hbase-2.5.11-bin.tar.gz .
wget http://apache.mirror.gtcomm.net/hbase/stable/hbase-2.5.11-bin.tar.gz
tar xvf hbase-2.5.11-bin.tar.gz
Rename hbase-2.5.11 --> hbase
.bashrc:
...
...
export HADOOP_HOME=/home/hadoop/hadoop-3.4.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export SQOOP_HOME=/home/hadoop/sqoop-1.4.7.bin__hadoop-2.6.0
export PATH=$PATH:$SQOOP_HOME/bin
export HBASE_HOME=/home/hadoop/hbase
export PATH=$PATH:$HBASE_HOME/bin
nano $HBASE_HOME/conf/hbase-env.sh
add:
export JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64
#
# pseudo-distributed mode:
# export HBASE_REGIONSERVERS=${HBASE_HOME}/conf/regionservers
# export HBASE_MANAGES_ZK=true
Standalone Mode / Pseudo-Distributed Mode:
nano $HBASE_HOME/conf/hbase-site.xml
change <configuration>...</configuration> to:
<configuration>
<!--
The following properties are set for running HBase as a single process on a
developer workstation. With this configuration, HBase is running in
"stand-alone" mode and without a distributed file system. In this mode, and
without further configuration, HBase and ZooKeeper data are stored on the
local filesystem, in a path under the value configured for `hbase.tmp.dir`.
This value is overridden from its default value of `/tmp` because many
systems clean `/tmp` on a regular basis. Instead, it points to a path within
this HBase installation directory.
Running against the `LocalFileSystem`, as opposed to a distributed
filesystem, runs the risk of data integrity issues and data loss. Normally
HBase will refuse to run in such an environment. Setting
`hbase.unsafe.stream.capability.enforce` to `false` overrides this behavior,
permitting operation. This configuration is for the developer workstation
only and __should not be used in production!__
See also https://hbase.apache.org/book.html#standalone_dist
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
-->
<!-- Standalone Mode -->
<property>
<name>hbase.rootdir</name>
<value>file:///home/hadoop/hbase/hbaseFiles</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/hadoop-3.4.1/zookeeper</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- Pseudo-Distributed Mode -->
<!--
<property>
<name>hbase.rootdir</name>
<value>hdfs://127.0.0.1:9000/hbase</value>
<description>
hadoop: core-site.xml
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
<description>
default
</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/hadoop-3.4.1/zookeeper</value>
</property>
<property>
<name>zookeeper.registry.async.get.timeout</name>
<value>30000</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
-->
</configuration>
Start Sequence:
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
$HBASE_HOME/bin/start-hbase.sh
$HBASE_HOME/bin/hbase shell
Jps
5635 NodeManager
6915 Jps
5302 ResourceManager
4790 DataNode
4604 NameNode
6077 HMaster
5006 SecondaryNameNode
Create a table
create 'test', 'cf'
list 'test'
describe 'test'
put data into your table
put 'test', 'row1', 'cf:a', 'value1'
put 'test', 'row2', 'cf:b', 'value2'
put 'test', 'row3', 'cf:b', 'value3'
scan 'test'
Get a single row of data.
get 'test', 'row1'
Ending Sequence:
exit # shell
$HBASE_HOME/bin/stop-hbase.sh
$HADOOP_HOME/sbin/stop-yarn.sh
$HADOOP_HOME/sbin/stop-dfs.sh
Pseudo-Distributed Mode:
See: hbase-site.xml and hbase-env.sh
jps
Output
14050 HMaster
23507 NodeManager
22821 SecondaryNameNode
22421 NameNode
22601 DataNode
24203 Jps
13899 HQuorumPeer
14270 HRegionServer
23119 ResourceManager
Master Status:
http://localhost:16010/master-status