Hadoop-3.2.1 using Docker 01
Description
We will create an instance of Hadoop Cluster within a Docker container.
This Hadoop Cluster will have:
- Namenode
- Datanode
- Node Manager
- Resource manager
- Hadoop history server
Objectives
- Run hadoop instance
- Create files in the HDFS
Prerequisites
- Ubuntu
- Docker
Set up Cluster
- Clone the repository
git clone https://github.com/ibm-developer-skills-network/ooxwv-docker_hadoop.git - Go to
cd ooxwv-docker_hadoop - Compose the docker application
docker-compose up -d - Run the namenode as a mounted drive on bash
Output
docker exec -it namenode /bin/bashroot@03d7b5c822b7:/#
# 03d7b5c822b7 - container id
Explore the hadoop environment
ls -1 /opt/hadoop-3.2.1/etc/hadoop/*.xml
Output
# root@03d7b5c822b7:/# ls -1 /opt/hadoop-3.2.1/etc/hadoop/*.xml
/opt/hadoop-3.2.1/etc/hadoop/capacity-scheduler.xml
/opt/hadoop-3.2.1/etc/hadoop/core-site.xml
/opt/hadoop-3.2.1/etc/hadoop/hadoop-policy.xml
/opt/hadoop-3.2.1/etc/hadoop/hdfs-site.xml
/opt/hadoop-3.2.1/etc/hadoop/httpfs-site.xml
/opt/hadoop-3.2.1/etc/hadoop/kms-acls.xml
/opt/hadoop-3.2.1/etc/hadoop/kms-site.xml
/opt/hadoop-3.2.1/etc/hadoop/mapred-site.xml
/opt/hadoop-3.2.1/etc/hadoop/yarn-site.xml
Create a file in the HDFS
-
In the HDFS, create a directory structure named
user/root/inputhdfs dfs -mkdir -p /user/root/input -
Copy all the hadoop configuration xml files into the input directory
hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml /user/root/input -
Check if the files have been copied
hdfs dfs -ls /user/root/inputOutput
# root@03d7b5c822b7:/# hdfs dfs -ls /user/root/input
Found 9 items
-rw-r--r-- 3 root supergroup 8260 2025-04-22 12:46 /user/root/input/capacity-scheduler.xml
-rw-r--r-- 3 root supergroup 1204 2025-04-22 12:46 /user/root/input/core-site.xml
-rw-r--r-- 3 root supergroup 11392 2025-04-22 12:46 /user/root/input/hadoop-policy.xml
-rw-r--r-- 3 root supergroup 1643 2025-04-22 12:46 /user/root/input/hdfs-site.xml
-rw-r--r-- 3 root supergroup 620 2025-04-22 12:46 /user/root/input/httpfs-site.xml
-rw-r--r-- 3 root supergroup 3518 2025-04-22 12:46 /user/root/input/kms-acls.xml
-rw-r--r-- 3 root supergroup 682 2025-04-22 12:46 /user/root/input/kms-site.xml
-rw-r--r-- 3 root supergroup 1647 2025-04-22 12:46 /user/root/input/mapred-site.xml
-rw-r--r-- 3 root supergroup 3484 2025-04-22 12:46 /user/root/input/yarn-site.xml -
Create a
data.txtfile in the current directory# data.txt:
curl https://raw.githubusercontent.com/ibm-developer-skills-network/ooxwv-docker_hadoop/master/SampleMapReduce.txt --output data.txtOutput
# root@03d7b5c822b7:/# curl https://raw.githubusercontent.com/ibm-developer-skills-network/ooxwv-docker_hadoop/master/SampleMapReduce.txt --output data.txt
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 6858 100 6858 0 0 21643 0 --:--:-- --:--:-- --:--:-- 21702 -
Copy the
data.txtfile into/user/roothdfs dfs -put data.txt /user/root/ -
Check if the file has been copied into the HDFS by viewing its content
hdfs dfs -cat /user/root/data.txtOutput
# root@03d7b5c822b7:/# hdfs dfs -cat /user/root/data.txt
2025-04-22 13:14:32,763 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
What is big data? More than volume, velocity and variety -
Get your head around the topic of big data
By J. Steven Perry
Published May 22, 2017
You’ve heard of Big Data, right? We’re all supposed to say yes, and Big Data is one of those topics I thought I understood until I tried explaining it. I realized that I needed to get my head around it at a high level. If you’re like I was, then this blog post is for you.
The Problem(s)
Any technology is only useful if it solves a problem (or problems). So what problem(s) does Big Data solve?
As we all know, there is data, lots of it: historical data, sure, but also new data generated from social media apps, click stream data from web applications, IoT sensor data, and on and on. The amount of data is larger than ever, coming in at ever-increasing rates, and in many different formats.
The business value in the data comes from the meaning we can harvest from it. And deriving business value from all that data is a big problem. Why? Let’s break it down.
Data Volume
People are more connected than ever before, and this interconnection leads to more and more data sources, resulting in an amount of data that is larger than ever before (and constantly growing). The increased volume of data requires ever increasing computing power in order to derive value (meaning) from the data. Traditional computing methods simply don’t work on the volume of data accumulating today!
Data Velocity
The speed and directions from which data come into the enterprise is increasing due to interconnection and advances in network technology, so it is coming in faster than we can make sense out of it [2]. And the faster the data come in and more varied the sources, the harder it is to derive value (meaning) from the data. Traditional computing methods don’t work on data coming in at today’s speeds!
Data Variety
More sources of data means more varieties of data in different formats: from traditional documents and databases, to semi-structured and unstructured data from click streams, GPS location data, social media apps, and IoT (to name a few). Different data formats means it’s tougher to derive value (meaning) from the data because it must all be extracted for processing in different ways. Traditional computing methods don’t work on all these different varieties of data!
What Big Data is NOT
Traditional data like documents and databases
It’s true, there are LOTS of documents and databases in the world, and while these sources contribute to Big Data, they themselves are not Big Data. The varieties of data that are being collected today is changing, and this is driving Big Data. Some of the data are structured, like traditional documents and databases but most are semi-structured, or unstructured.
Just a synonym for “lots of data”
Big Data is much more than just a “lot of data”.
Lots of data is driving Big Data, but to associate the volume of data with the term Big Data and stop there is a mistake.
It’s not about the data
Big Data is not about the data [1], any more than philosophy is about words. Big Data is about the value that can be extracted from the data, or, the MEANING contained in the data.
A single technology – rather it’s an entire technology ecosystem
Big Data is a way of harvesting raw data from multiple, disparate data sources, storing the data for use by analytics programs, and using the raw data to derive value (meaning) from the data in a whole new ways. We’re talking data from traditional business applications like CRM and web applications, combined with data from a growing number of sensors (IoT), and social media like Facebook, Twitter, and LinkedIn.
This means that no single technology can be called Big Data, which requires a tightly coordinated ecosystem of data acquisition, storage, and application technologies to make it work.
A trend
Big Data is the natural evolution of the way to cope with the vast quantities, types, and volume of data from today’s applications. The volume, velocity and variety of data coming into today’s enterprise means that these problems can only be solved by a solution that is equally organic, and capable of continued evolution.
In other words, it’s the ways we are using software and creating the data that are driving Big Data.
Unless we change the ways we use software (like apps), platforms (like social media), and core infrastructure technologies (like the internet), Big Data is here to stay. Case in point: Give up Snapchat? LinkedIn? Facebook? Twitter? Not gonna happen.
The Solution
In my opinion, Big Data is really a misnomer. As I mentioned earlier, Big Data is no more about the data than philosophy is about words. Big Data is about MEANING derived from the data. Maybe we should call it “Big Meaning” (granted, that’s not as catchy, but it makes more sense to me).
So how does Big Meaning, um, I mean Big Data, solve the problems of data volume, velocity and variety?
Volume
Well, first, the data has to be stored somewhere, because without somewhere to store the data, it cannot be made available for analysis.
Fortunately, storage is cheaper, more reliable, and – thanks to the cloud – more accessible than ever.
Velocity
We first need to deal with the speed at which the data comes in, and automated, intelligent systems that run lights-out, 24 x 7 x 365 help harvest patterns (meaning) in the data that would be impossible to detect through manual analysis. Advances in machine learning techniques help deal with the Velocity problem. Artificial neural networks, for example, can be trained to detect patterns, apply that knowledge to make predictions, and even adapt to the changing data on the fly.
Variety
Then there are the variety of directions (sources) from which the data come in. Patterns in the data are only good if we can look at what has happened before (historical data) and use them to predict something helpful or interesting about the future.
However, as the variety of data sources continues to grow, so does the complexity of harvesting meaning from the data. Human beings simply cannot handle the load, which is where techniques like deep learning come into play. Deep learning networks can figure out how to make sense of the data’s various input formats and feed that into other networks to harvest meaning from the data.
Conclusion
The term Big Data really means “harvesting meaning from data” that is coming in faster, from more sources, and in more varied formats than ever before. We should probably call it Big Meaning. Because Big Data is really about the value in the data, rather than the data itself.
Rather than being a single technology, Big Data is an ecosystem of coordinated techniques and technologies that derive business value from the mountains of data produced in today’s world.
root@03d7b5c822b7:/#
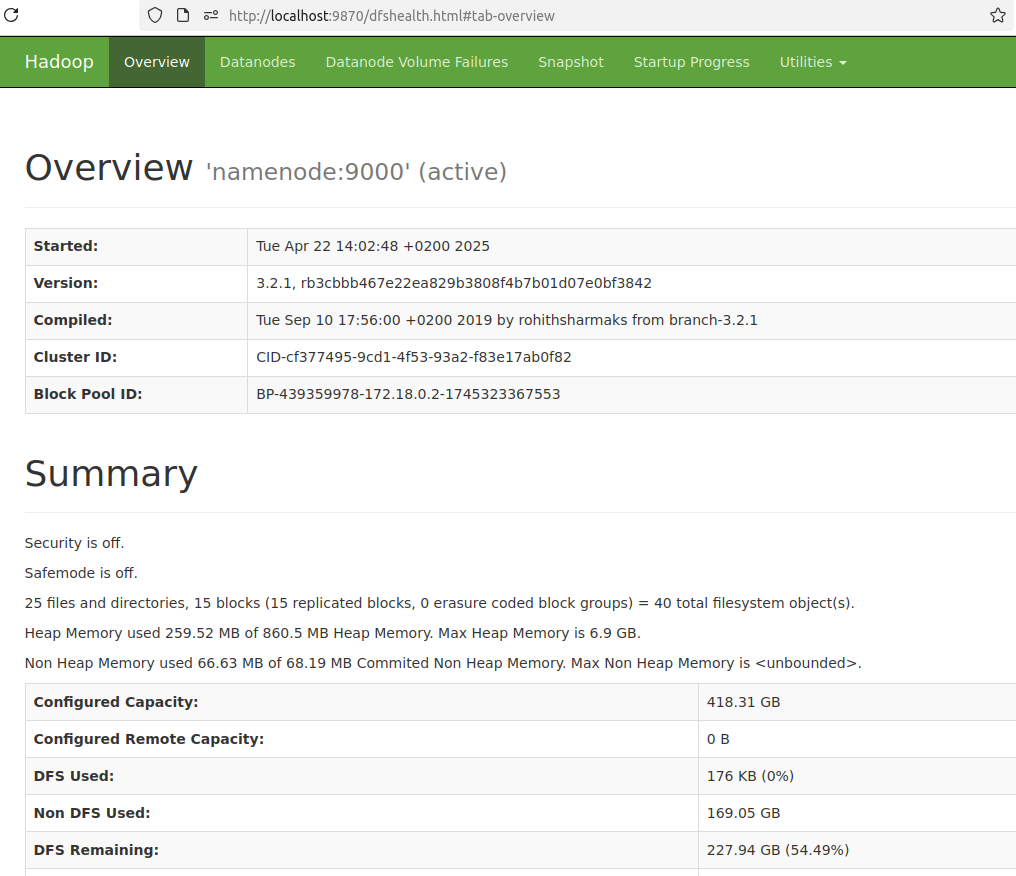
View the HDFS on GUI
localhost:9870
- Overview
/user/root/input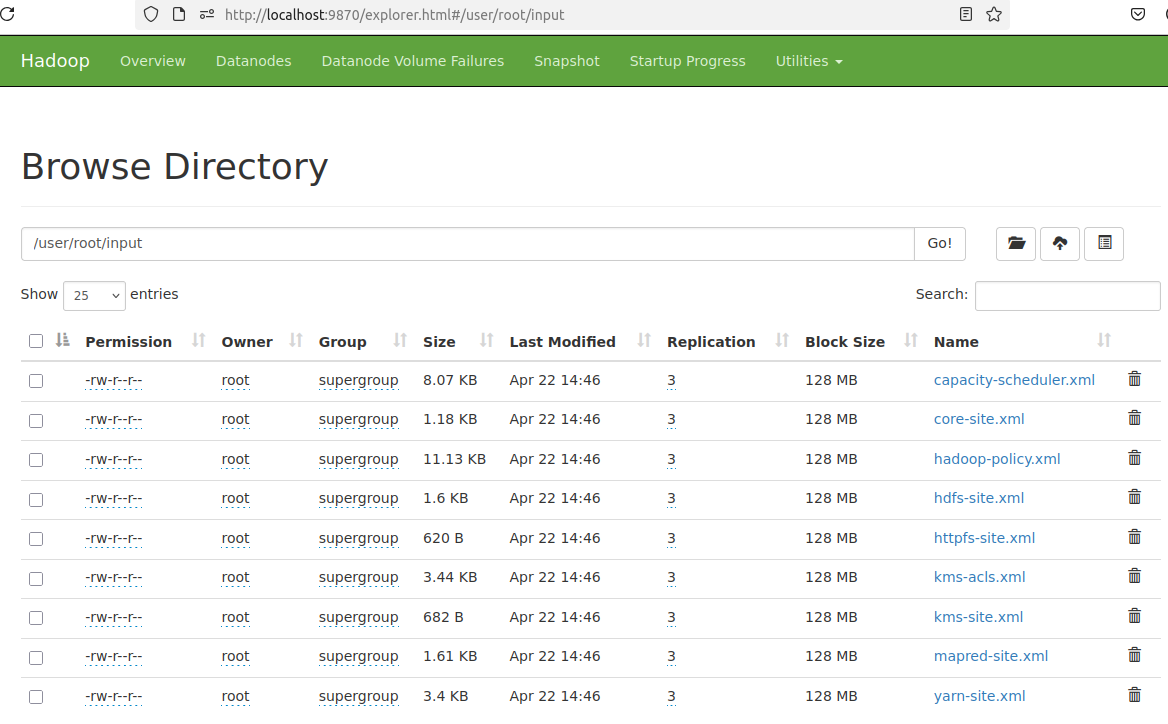
/user/root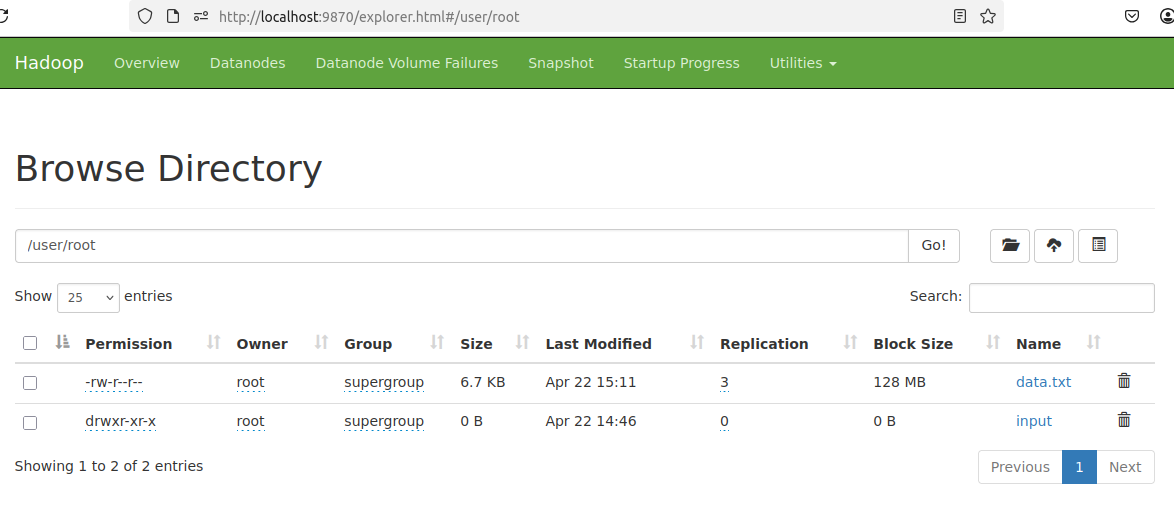
Based on: