Spark Architecture
Understanding Spark Architecture: How It All Comes Together
Spark Architecture: A Deep Dive
Cluster Mode Overview
At its core, Spark is a distributed processing framework designed to handle large datasets across multiple machines (or nodes). Spark’s key strength lies in its speed — it processes data up to 100 times faster than traditional systems like Hadoop MapReduce by storing intermediate data in memory and processing tasks in parallel.
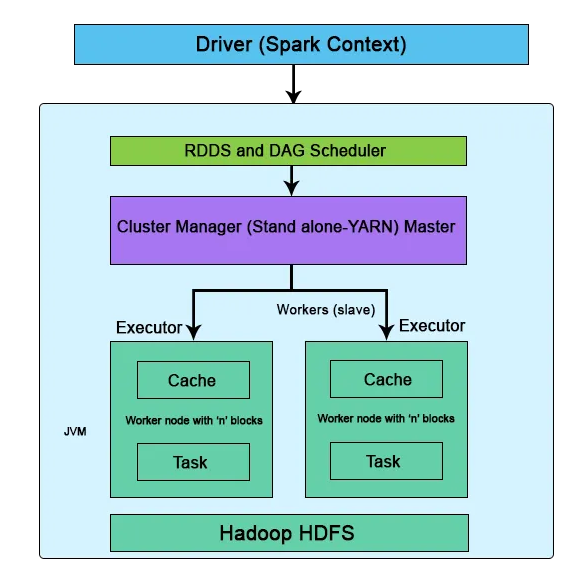
The Apache Spark framework uses a master-slave architecture that consists of a driver, which runs as a master node, and many executors that run across as worker nodes in the cluster. Apache Spark can be used for batch processing and real-time processing as well.
Spark divides large datasets into smaller pieces and processes them simultaneously across multiple machines, ensuring fast, scalable data processing.
The Spark Driver (Master)
The driver is the program or process responsible for coordinating the execution of the Spark application. It runs the main function and creates the SparkContext, which connects to the cluster manager.
It manages job scheduling and converts your code into tasks, assigns them to Executors, and monitors progress. Once tasks are completed, the Driver collects the results from each task, assembling the final answer. It’s like the project manager overseeing everything.
sparkContext
SparkContext is the entry point for any Spark functionality. It represents the connection to a Spark cluster and can be used to create RDDs (Resilient Distributed Datasets), accumulators, and broadcast variables. SparkContext also coordinates the execution of tasks.
The Spark Executors (Slaves)
These are the workers who process data. They are launched on worker nodes and communicate with the driver program and cluster manager. Executors run tasks concurrently and store data in memory or disk for caching and intermediate storage.
The Cluster Manager
The Cluster Manager is responsible for allocating resources and managing the cluster on which the Spark application runs. Spark supports various cluster managers like Apache Mesos, Hadoop YARN, and standalone cluster manager.
Spark uses a Cluster Manager to allocate resources like CPU, memory, and storage. Think of the Cluster Manager as a traffic controller, ensuring that all the machines (nodes) in the cluster are effectively utilized. This ensures each application has the resources it needs to run efficiently. Spark supports 3 types of cluster managers:
- Standalone Mode: Spark’s built-in cluster-manager, is ideal for small to medium clusters. (easy to set up)
- Hadoop YARN (Yet Another Resource Negotiator): Common in Hadoop environments. It manages resources across multiple applications running on a Hadoop cluster.
- Kubernetes: Popular for dynamic and cloud-based, containerized workloads.
- Apache Mesos: A general cluster manager that can also run Hadoop MapReduce and service applications. (Deprecated)
Task
A task is the smallest unit of work in Spark, representing a unit of computation that can be performed on a single partition of data. The driver program divides the Spark job into tasks and assigns them to the executor nodes for execution.
RDD (Resilient Distributed Datasets)
RDDs are the fundamental data structures in Spark. They are immutable, distributed collections of objects that can be processed in parallel. RDDs provide fault tolerance by tracking the lineage of transformations to recompute lost data.
RDD includes all sorts of Python, Scala, or Java objects for users to use.
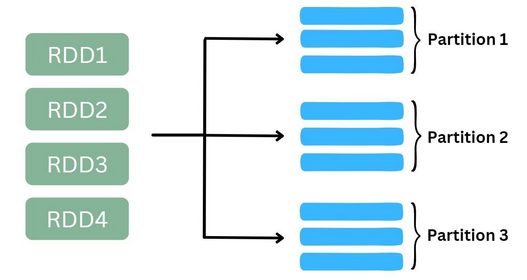
Each dataset in RDD is divided into logical partitions. These partitions are stored and processed on various machines of a cluster.
DAG (Directed Acyclic Graph)
A DAG represents a series of transformations on data. Spark optimizes the execution plan by constructing a DAG of stages. This graph helps in efficient pipelining of operations and task scheduling.
The DAG in Spark/PySpark is a fundamental concept that plays a crucial role in the Spark execution model. The DAG is “directed” because the operations are executed in a specific order, and “acyclic” because there are no loops or cycles in the execution plan. This means that each stage depends on the completion of the previous stage, and each task within a stage can run independently of the other.
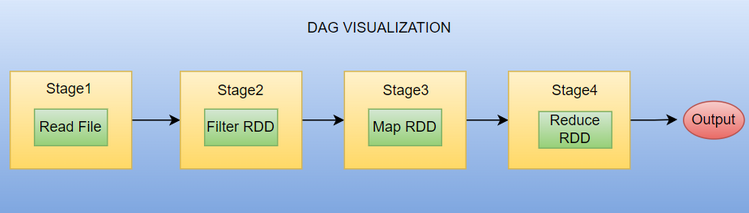
At a high level, a DAG represents the logical execution plan of a Spark job. When a Spark application is submitted, Spark translates the high-level operations (such as transformations and actions) specified in the application code into a DAG of stages and tasks.
DAG Scheduler
The DAG Scheduler divides the operator graph into stages and submits them to the Task Scheduler. It optimizes the execution plan by rearranging and combining operations where possible, grouping them into stages, and sending these stages to the Task Scheduler.
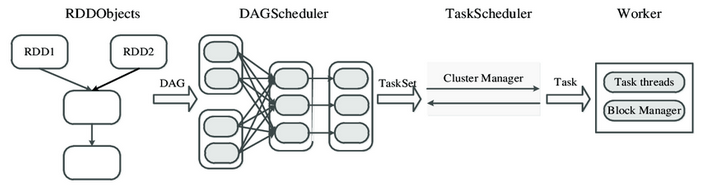
Task Scheduler
The Task Scheduler launches tasks via the cluster manager. It sends tasks to the executor nodes, ensuring parallel execution across the cluster. Tasks for each stage are launched according to the number of partitions.
Built-in Libraries
Apache Spark comes with a rich set of built-in libraries that cater to various data processing needs: