Binary Classification
Binary classification is a type of supervised learning where the goal is to classify data points into one of two distinct categories. Examples include:
- Spam detection: Email is either "spam" or "not spam."
- Medical diagnosis: A patient has "disease" or "no disease."
- Fraud detection: A transaction is "fraudulent" or "genuine."
1. Steps in Binary Classification
Step 1: Data Collection
- Gather labeled data (features and corresponding class labels).
- Example dataset: Titanic survival (features like age, sex, ticket class → survived or not).
Step 2: Data Preprocessing
- Handle missing values.
- Encode categorical variables (e.g., one-hot encoding for categorical features).
- Scale numerical features using normalization or standardization.
- Split dataset into training and test sets (e.g., 80% train, 20% test).
Step 3: Choosing a Model
Common binary classification algorithms:
- Logistic Regression: Simple and interpretable.
- Decision Trees: Can capture complex relationships.
- Random Forest: Ensemble model for better generalization.
- Support Vector Machines (SVM): Effective in high-dimensional spaces.
- Neural Networks: Useful for complex and large datasets.
- Naïve Bayes: Good for text classification (e.g., spam detection).
- Gradient Boosting (XGBoost, LightGBM, CatBoost): Highly effective for structured data.
Step 4: Model Training
- Use training data to fit the model.
- Optimize hyperparameters (e.g., learning rate, depth for trees, kernel for SVM).
Step 5: Model Evaluation
Key performance metrics:
- Accuracy: (Correct predictions) / (Total predictions)
- Precision: TP / (TP + FP) – How many predicted positives are actual positives.
- Recall (Sensitivity): TP / (TP + FN) – Ability to detect positive class.
- F1-Score: Harmonic mean of precision and recall.
- ROC-AUC Score: Measures the model's ability to distinguish between classes.
Step 6: Model Optimization
- Feature selection to remove irrelevant data.
- Hyperparameter tuning (GridSearchCV, RandomizedSearchCV).
- Handling imbalanced data (e.g., oversampling, undersampling, SMOTE).
Step 7: Model Deployment
- Deploy as an API, web service, or integrate into an application.
- Monitor model performance over time.
Classification in Machine Learning: An Introduction
Classification is a supervised machine learning method where the model tries to predict the correct label of a given input data. In classification, the model is fully trained using the training data, and then it is evaluated on test data before being used to perform prediction on new unseen data.
https://www.datacamp.com/blog/classification-machine-learning
What is Binary Classification?
In machine learning, binary classification is a supervised learning algorithm that categorizes new observations into one of two classes.
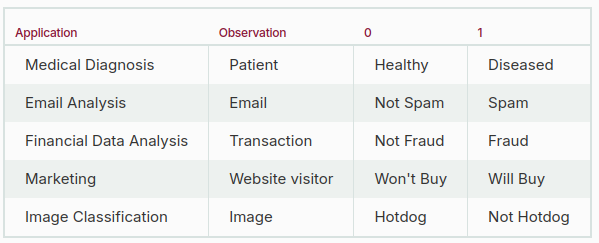
The following are a few binary classification applications, where the 0 and 1 columns are two possible classes for each observation:
...
https://www.learndatasci.com/glossary/binary-classification/
Binary Classification for Beginners
Binary classification can help predict outcomes. Explore how it relates to machine learning and binary classification applications in different professional fields.
Binary classification is a type of machine learning algorithm used in many industries, such as health care and finance, as well as in web-based applications. It provides powerful insights, including identifying patterns and making predictions based on past data. Overall, binary classification models help businesses make better decisions.
...
Classification in Machine Learning
In machine learning and statistics, classification is a supervised learning method in which a computer software learns from data and makes new observations or classifications.
Classification is the process of dividing a set of data into distinct classes. It may be applied to both organized and unstructured data. Predicting the class of data points is the first step in the procedure. Target, label, and categories are common terms for the classes.
Approximating the mapping function from discrete input variables to discrete output variables is the problem of classification predictive modeling. The basic objective is to figure out which category or class the new data belongs in.
There are a couple of different types of classification tasks in machine learning, namely:
- Binary Classification – This is what we’ll discuss a bit more in-depth here. Classification problems with two class labels are referred to as binary classification. In most binary classification problems, one class represents the normal condition and the other represents the aberrant condition.
- Multi-Class Classification – Classification jobs with more than two class labels are referred to as multi-class classification. Multi-class classification, unlike binary classification, does not distinguish between normal and pathological results. Instead, examples are assigned to one of a number of pre-defined classes.
- Multi-Label Classification – Classification problems with two or more class labels, where one or more class labels may be anticipated for each case, are referred to as multi-label classification. It differs from binary and multi-class classification, which predict a single class label for each case.
...