Glossary
SerDes (Data Types and Serialization)
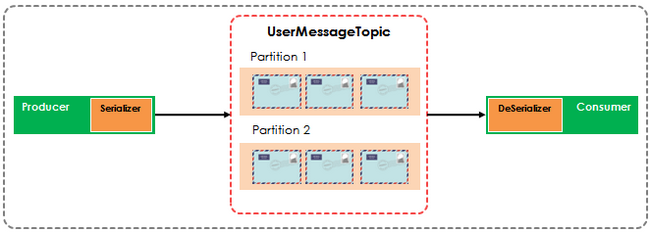
Every Kafka Streams application must provide SerDes (Serializer/Deserializer) for the data types of record keys and record values (e.g. java.lang.String) to materialize the data when necessary. Operations that require such SerDes information include: stream(), table(), to(), through(), groupByKey(), groupBy().
You can provide SerDes by using either of these methods:
- By setting default SerDes in the java.util.Properties config instance.
- By specifying explicit SerDes when calling the appropriate API methods, thus overriding the defaults.
...
https://kafka.apache.org/20/documentation/streams/developer-guide/datatypes
Kafka Streams Topology
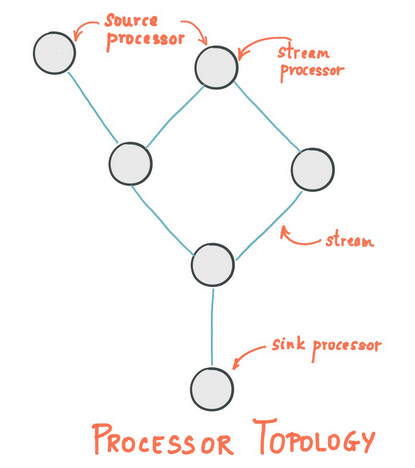
A processor topology or simply topology defines the stream processing computational logic for your application, i.e., how input data is transformed into output data. A topology is a graph of stream processors (nodes) that are connected by streams (edges) or shared state stores. There are two special processors in the topology:
- Source Processor: A source processor is a special type of stream processor that does not have any upstream processors. It produces an input stream to its topology from one or multiple Kafka topics by consuming records from these topics and forward them to its down-stream processors.
- Sink Processor: A sink processor is a special type of stream processor that does not have down-stream processors. It sends any received records from its up-stream processors to a specified Kafka topic.
A stream processing application – i.e., your application – may define one or more such topologies, though typically it defines only one. Developers can define topologies either via the low-level Processor API or via the Kafka Streams DSL, which builds on top of the former.
The kafka streams topology is where we specify the logic:
final StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> views = builder.stream(
"input-topic",
Consumed.with(stringSerde, stringSerde)
);
KTable<String, Long> totalViews = views
.mapValues(v -> Long.parseLong(v))
.groupByKey(Grouped.with(stringSerde, longSerde))
.reduce(Long::sum);
totalViews.toStream().to("output-topic", Produced.with(stringSerde, longSerde));
We are creating a KStream object called views to read data from the kafka topic input-topic. In this topic both the key and value are strings. Hence we use string serde for both the key and the value
Next we are created a KTable object with key as string and value as long. This is the object where we will store our computation result.
We are using java lambda expressions to achieve the following
- Convert the value to Long, since the value here is the video view count
- Group all the same video titles together.
- For the Grouped video title, calculate the sum.
Finally the total video view count is written to a kafka topic called output-topic. In this topic, the key is a string and the value is a Long.
Kafka Streams offers two ways to define the stream processing topology: the Kafka Streams DSL provides the most common data transformation operations such as map, filter, join and aggregations out of the box; the lower-level Processor API allows developers define and connect custom processors as well as to interact with state stores.
A processor topology is merely a logical abstraction for your stream processing code. At runtime, the logical topology is instantiated and replicated inside the application for parallel processing (see Stream Partitions and Tasks for details).
Kafka Streams DSL
Kafka Streams DSL (Domain-Specific Language) is a high-level, declarative language built on top of the core Kafka Streams library. It provides a simpler, more readable way to define common stream processing operations like filtering, mapping, aggregation, and windowing.
Here’s a basic example of using the Streams DSL to count the number of events per type
// Starts building the stream processing topology.
StreamsBuilder builder = new StreamsBuilder();
// Reads events from the "event-stream" topic, with each event keyed // by a String and valued by an Event object.
KStream<String, Event> events = builder.stream("event-stream");
// Events are grouped by their type using event.getType(), and then // counted. This operation produces a KTable that continuously // updates as new events arrive.
KTable<String, Long> eventCounts = events
.groupBy((key, event) -> event.getType())
.count();
// Converts the KTable back to a KStream and writes the counts of each event type to the "event-counts-output" topic.
eventCounts.toStream().to("event-counts-output");