Confluent Platform
Running locally with Confluent Platform and its main components using Docker containers.
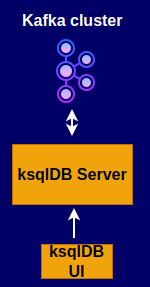
In this quick start, you create Apache Kafka® topics, use Kafka Connect to generate mock data to those topics, and create ksqlDB streaming queries on those topics. You then go to Confluent Control Center to monitor and analyze the event streaming queries. When you finish, you’ll have a real-time app that consumes and processes data streams by using familiar SQL statements.
I. Download and start Confluent Platform
Quick Start for Confluent Platform
wget https://raw.githubusercontent.com/confluentinc/cp-all-in-one/7.8.0-post/cp-all-in-one-kraft/docker-compose.yml
As a result, you get: docker-compose.yml:
---
services:
broker:
image: confluentinc/cp-kafka:7.8.0
hostname: broker
container_name: broker
ports:
- "9092:9092"
- "9101:9101"
environment:
KAFKA_NODE_ID: 1
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: 'CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT'
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker:29092,PLAINTEXT_HOST://localhost:9092'
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_PROCESS_ROLES: 'broker,controller'
KAFKA_CONTROLLER_QUORUM_VOTERS: '1@broker:29093'
KAFKA_LISTENERS: 'PLAINTEXT://broker:29092,CONTROLLER://broker:29093,PLAINTEXT_HOST://0.0.0.0:9092'
KAFKA_INTER_BROKER_LISTENER_NAME: 'PLAINTEXT'
KAFKA_CONTROLLER_LISTENER_NAMES: 'CONTROLLER'
KAFKA_LOG_DIRS: '/tmp/kraft-combined-logs'
# Replace CLUSTER_ID with a unique base64 UUID using "bin/kafka-storage.sh random-uuid"
# See https://docs.confluent.io/kafka/operations-tools/kafka-tools.html#kafka-storage-sh
CLUSTER_ID: 'MkU3OEVBNTcwNTJENDM2Qk'
schema-registry:
image: confluentinc/cp-schema-registry:7.8.0
hostname: schema-registry
container_name: schema-registry
depends_on:
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker:29092'
SCHEMA_REGISTRY_LISTENERS: http://0.0.0.0:8081
connect:
image: cnfldemos/cp-server-connect-datagen:0.6.4-7.6.0
hostname: connect
container_name: connect
depends_on:
- broker
- schema-registry
ports:
- "8083:8083"
environment:
CONNECT_BOOTSTRAP_SERVERS: 'broker:29092'
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_GROUP_ID: compose-connect-group
CONNECT_CONFIG_STORAGE_TOPIC: docker-connect-configs
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_FLUSH_INTERVAL_MS: 10000
CONNECT_OFFSET_STORAGE_TOPIC: docker-connect-offsets
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: docker-connect-status
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.storage.StringConverter
CONNECT_VALUE_CONVERTER: io.confluent.connect.avro.AvroConverter
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: http://schema-registry:8081
# CLASSPATH required due to CC-2422
CLASSPATH: /usr/share/java/monitoring-interceptors/monitoring-interceptors-7.8.0.jar
CONNECT_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
CONNECT_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
CONNECT_PLUGIN_PATH: "/usr/share/java,/usr/share/confluent-hub-components"
control-center:
image: confluentinc/cp-enterprise-control-center:7.8.0
hostname: control-center
container_name: control-center
depends_on:
- broker
- schema-registry
- connect
- ksqldb-server
ports:
- "9021:9021"
environment:
CONTROL_CENTER_BOOTSTRAP_SERVERS: 'broker:29092'
CONTROL_CENTER_CONNECT_CONNECT-DEFAULT_CLUSTER: 'connect:8083'
CONTROL_CENTER_CONNECT_HEALTHCHECK_ENDPOINT: '/connectors'
CONTROL_CENTER_KSQL_KSQLDB1_URL: "http://ksqldb-server:8088"
CONTROL_CENTER_KSQL_KSQLDB1_ADVERTISED_URL: "http://localhost:8088"
CONTROL_CENTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
CONTROL_CENTER_REPLICATION_FACTOR: 1
CONTROL_CENTER_INTERNAL_TOPICS_PARTITIONS: 1
CONTROL_CENTER_MONITORING_INTERCEPTOR_TOPIC_PARTITIONS: 1
CONFLUENT_METRICS_TOPIC_REPLICATION: 1
PORT: 9021
ksqldb-server:
image: confluentinc/cp-ksqldb-server:7.8.0
hostname: ksqldb-server
container_name: ksqldb-server
depends_on:
- broker
- connect
ports:
- "8088:8088"
environment:
KSQL_CONFIG_DIR: "/etc/ksql"
KSQL_BOOTSTRAP_SERVERS: "broker:29092"
KSQL_HOST_NAME: ksqldb-server
KSQL_LISTENERS: "http://0.0.0.0:8088"
KSQL_CACHE_MAX_BYTES_BUFFERING: 0
KSQL_KSQL_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
KSQL_PRODUCER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringProducerInterceptor"
KSQL_CONSUMER_INTERCEPTOR_CLASSES: "io.confluent.monitoring.clients.interceptor.MonitoringConsumerInterceptor"
KSQL_KSQL_CONNECT_URL: "http://connect:8083"
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_REPLICATION_FACTOR: 1
KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: 'true'
KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: 'true'
ksqldb-cli:
image: confluentinc/cp-ksqldb-cli:7.8.0
container_name: ksqldb-cli
depends_on:
- broker
- connect
- ksqldb-server
entrypoint: /bin/sh
tty: true
ksql-datagen:
image: confluentinc/ksqldb-examples:7.8.0
hostname: ksql-datagen
container_name: ksql-datagen
depends_on:
- ksqldb-server
- broker
- schema-registry
- connect
command: "bash -c 'echo Waiting for Kafka to be ready... && \
cub kafka-ready -b broker:29092 1 40 && \
echo Waiting for Confluent Schema Registry to be ready... && \
cub sr-ready schema-registry 8081 40 && \
echo Waiting a few seconds for topic creation to finish... && \
sleep 11 && \
tail -f /dev/null'"
environment:
KSQL_CONFIG_DIR: "/etc/ksql"
STREAMS_BOOTSTRAP_SERVERS: broker:29092
STREAMS_SCHEMA_REGISTRY_HOST: schema-registry
STREAMS_SCHEMA_REGISTRY_PORT: 8081
rest-proxy:
image: confluentinc/cp-kafka-rest:7.8.0
depends_on:
- broker
- schema-registry
ports:
- 8082:8082
hostname: rest-proxy
container_name: rest-proxy
environment:
KAFKA_REST_HOST_NAME: rest-proxy
KAFKA_REST_BOOTSTRAP_SERVERS: 'broker:29092'
KAFKA_REST_LISTENERS: "http://0.0.0.0:8082"
KAFKA_REST_SCHEMA_REGISTRY_URL: 'http://schema-registry:8081'
Start the Confluent Platform
docker-compose up -d
Result:
# ...
Status: Downloaded newer image for confluentinc/cp-kafka-rest:7.8.0
Creating broker ... done
Creating schema-registry ... done
Creating rest-proxy ... done
Creating connect ... done
Creating ksqldb-server ... done
Creating control-center ... done
Creating ksql-datagen ... done
Creating ksqldb-cli ... done
Verify that the services are up and running:
docker-compose ps
Your output should resemble:
Name Command State Ports
---------------------------------------------------------------------------------------------------------
broker /etc/confluent/docker/run Up 0.0.0.0:9092->9092/tcp, 0.0.0.0:9101->9101/tcp
connect /etc/confluent/docker/run Up 0.0.0.0:8083->8083/tcp, 9092/tcp
control-center /etc/confluent/docker/run Up 0.0.0.0:9021->9021/tcp
ksql-datagen bash -c echo Waiting for K ... Up
ksqldb-cli /bin/sh Up
ksqldb-server /etc/confluent/docker/run Up 0.0.0.0:8088->8088/tcp
rest-proxy /etc/confluent/docker/run Up 0.0.0.0:8082->8082/tcp
schema-registry /etc/confluent/docker/run Up 0.0.0.0:8081->8081/tcp
II. Uninstall and clean up
Stop Docker
docker-compose stop
Prune the Docker
docker system prune -a --volumes --filter "label=io.confluent.docker"
III. Create Kafka topics for storing your data
In Confluent Platform, real-time streaming events are stored in a Kafka topic.
In this step, you create two topics. The topics are named
- pageviews
- users.
Create the pageviews topic
- Navigate to Control Center at http://localhost:9021
- Click the controlcenter.cluster tile.
- Click Topics to open the topics list.
- Click + Add topic to start creating the pageviews topic; with defaults.
Result:
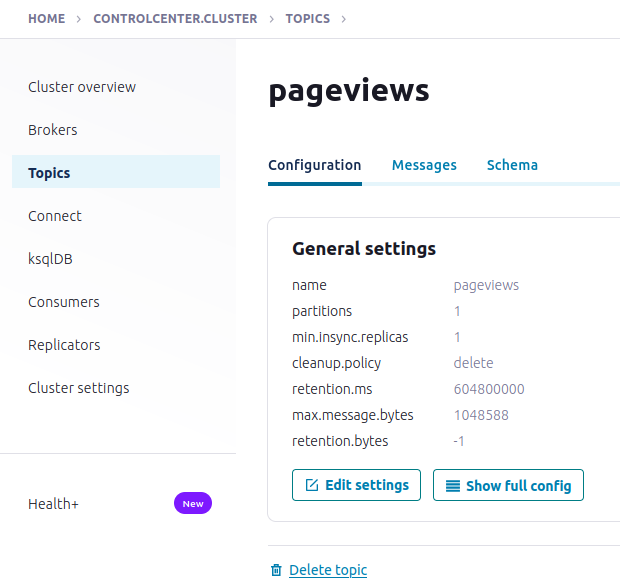
Create the users topic with defaults
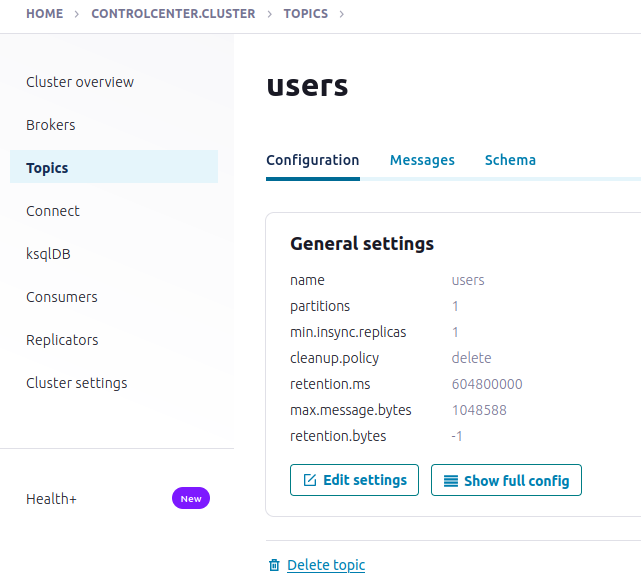
IV. Generate mock data
In Confluent Platform, you get events from an external source by using Kafka Connect. Connectors enable you to stream large volumes of data to and from your Kafka cluster. Confluent publishes many connectors for integrating with external systems, like MongoDB and Elasticsearch. For more information, see the Kafka Connect Overview page.
In this step, you run the Datagen Source Connector to generate mock data. The mock data is stored in the pageviews and users topics that you created previously. To learn more about installing connectors, see Install Self-Managed Connectors.
- At http://localhost:9021 click Connect
- Click the connect-default
- Click Add connector
- Select the DatagenConnector tile
- To see source connectors only, click Filter by category and select Sources.
- In the Name field, enter datagen-pageviews as the name of the connector.
- Common section:
- Key converter class: org.apache.kafka.connect.storage.StringConverter
- General section:
- kafka.topic: Choose pageviews from the dropdown menu
- max.interval: 100
- quickstart: pageviews
- Click Next to review the connector configuration
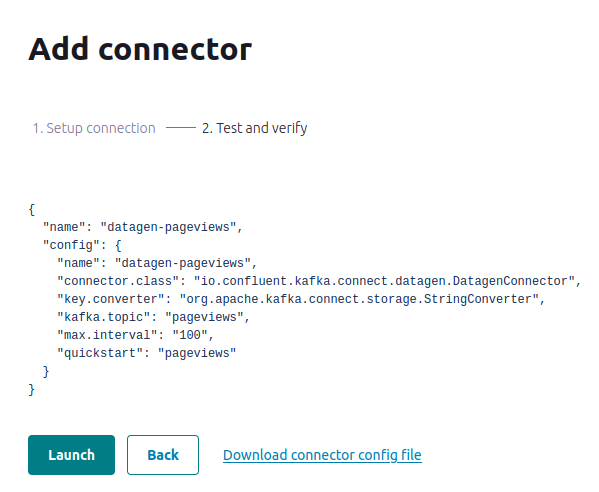
- Click Launch
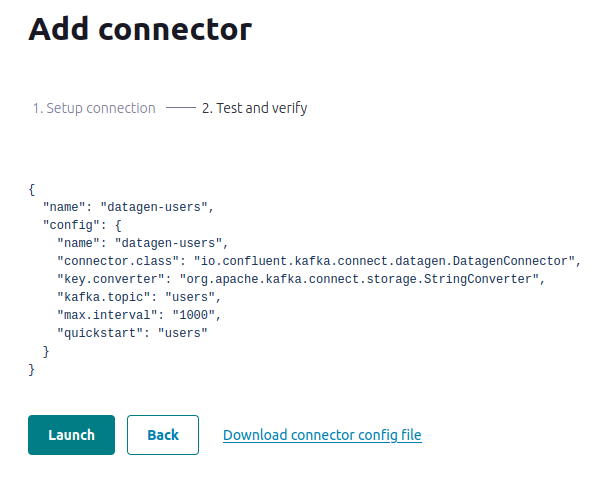
Run a second instance of the Datagen Source connector to produce mock data to the users topic.
- In the Name field, enter datagen-users as the name of the connector.
- Common section:
- Key converter class: org.apache.kafka.connect.storage.StringConverter
- General section:
- kafka.topic: Choose users from the dropdown menu
- max.interval: 1000
- quickstart: users
- Click Next to review the connector configuration. When you’re satisfied with the settings, click Launch.
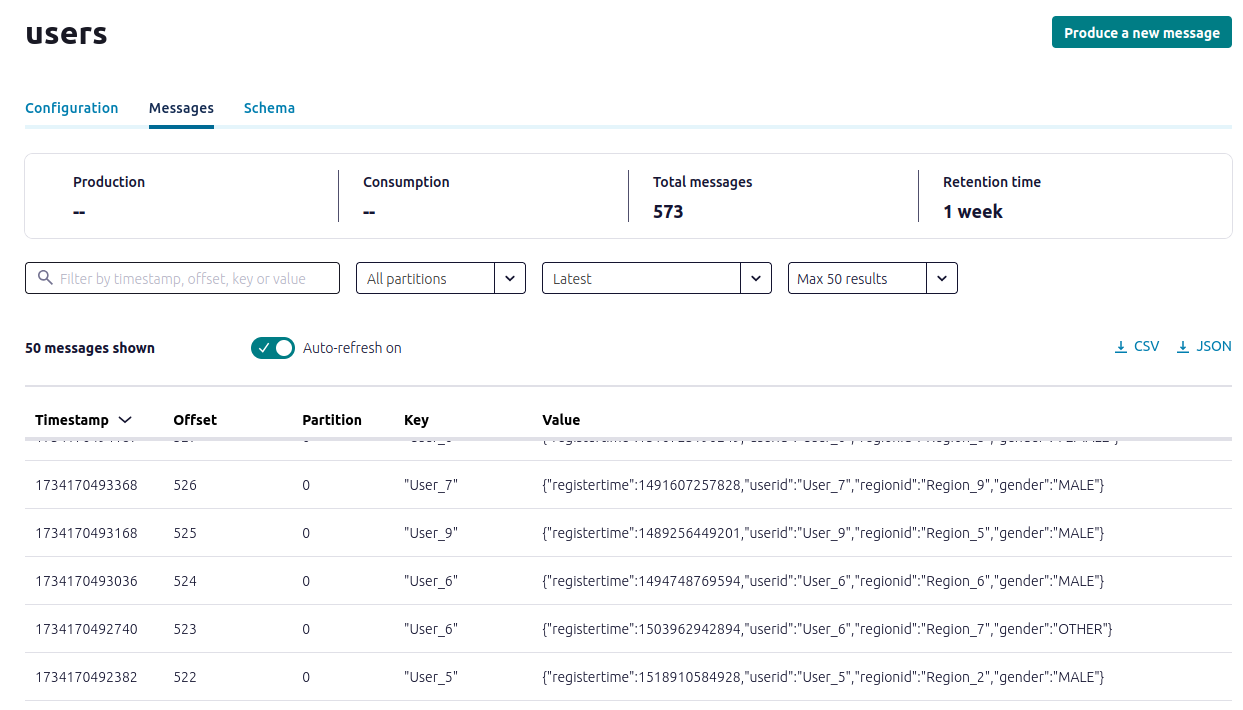
- In the navigation menu, click Topics and in the list, click users.
- Click Messages to confirm that the datagen-users connector is producing data to the users topic.
Inspect the schema of a topic
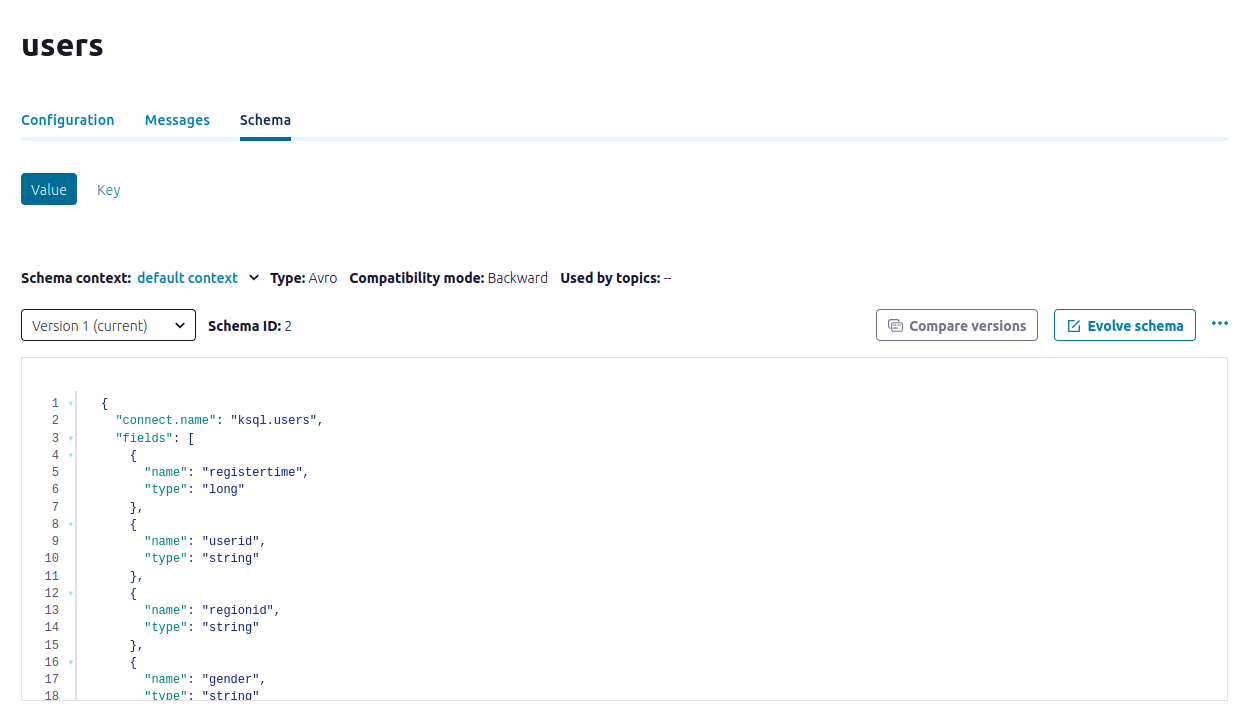
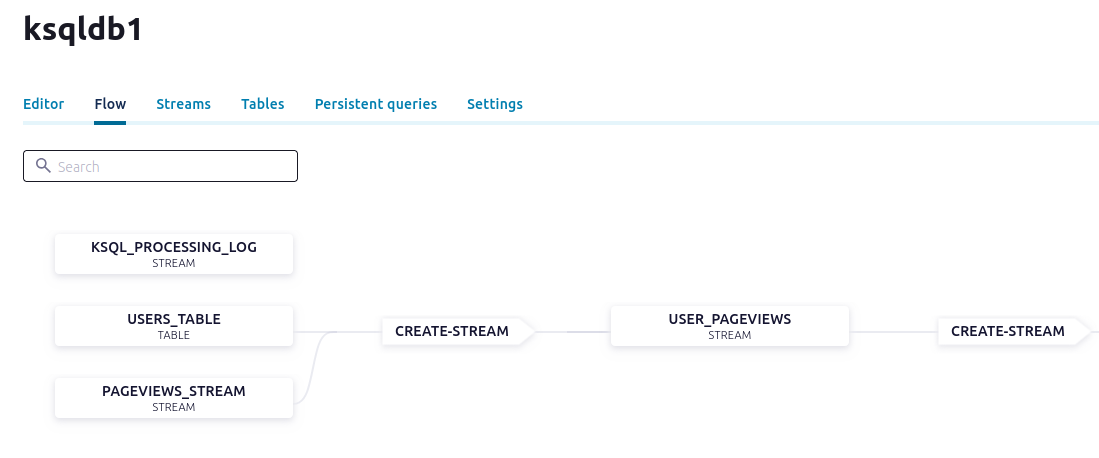
V. Create a stream and table by using SQL statements
In this step, you create a stream for the pageviews topic and a table for the users topic by using familiar SQL syntax.
A stream is a an immutable, append-only collection that represents a series of historical facts, or events. After a row is inserted into a stream, the row can never change. You can append new rows at the end of the stream, but you can’t update or delete existing rows.
A table is a mutable collection that models change over time. It uses row keys to display the most recent data for each key. All but the newest rows for each key are deleted periodically. Also, each row has a timestamp, so you can define a windowed table which enables controlling how to group records that have the same key for stateful operations – like aggregations and joins – into time spans. Windows are tracked by record key.
Together, streams and tables comprise a fully realized database. For more information, see Stream processing.
CREATE STREAM
- In the Dashboard menu, click ksqlDB.
- Open the ksqldb1 page.
- Copy the following SQL into the editor window. This statement registers a stream, named pageviews_stream, on the pageviews topic. Stream and table names are not case-sensitive.
CREATE STREAM pageviews_stream
WITH (KAFKA_TOPIC='pageviews', VALUE_FORMAT='AVRO');
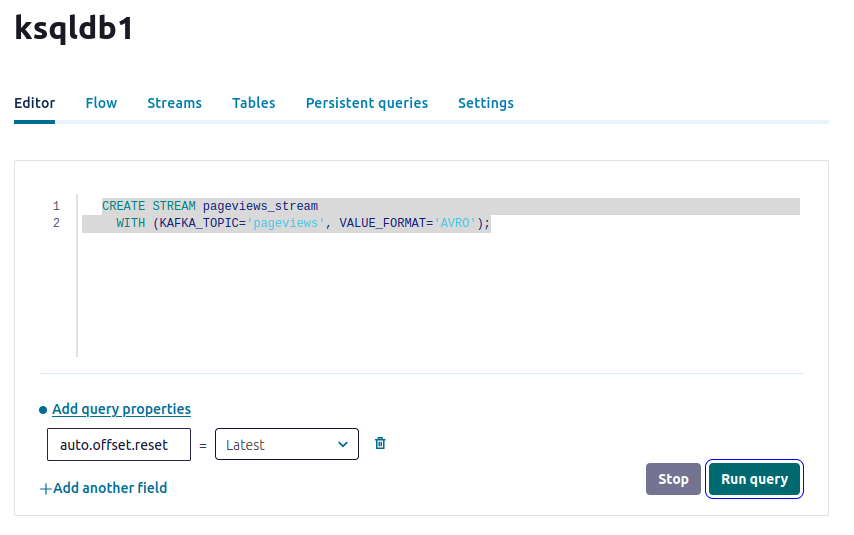
Run query
Use a SELECT query to confirm that data is moving through your stream.
SELECT * FROM pageviews_stream EMIT CHANGES;
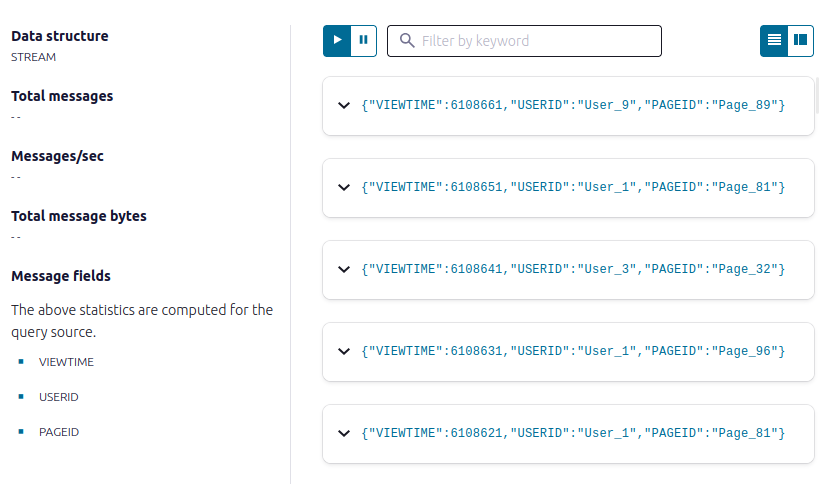
- Click Stop to end the SELECT query.
Stopping the SELECT query doesn’t stop data movement through the stream.
CREATE TABLE
CREATE TABLE users_table (id VARCHAR PRIMARY KEY)
WITH (KAFKA_TOPIC='users', VALUE_FORMAT='AVRO');
Output
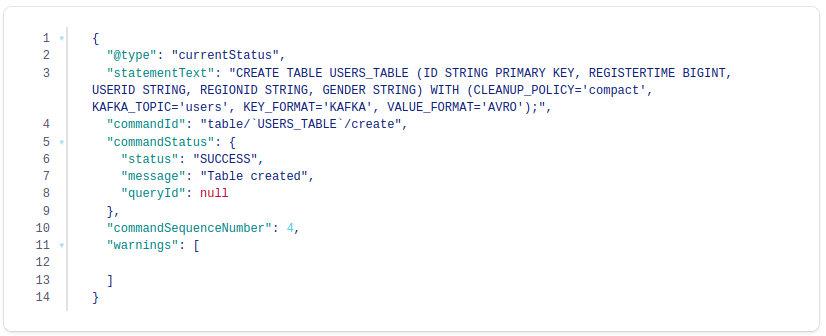
Inspect the schemas of your stream and table
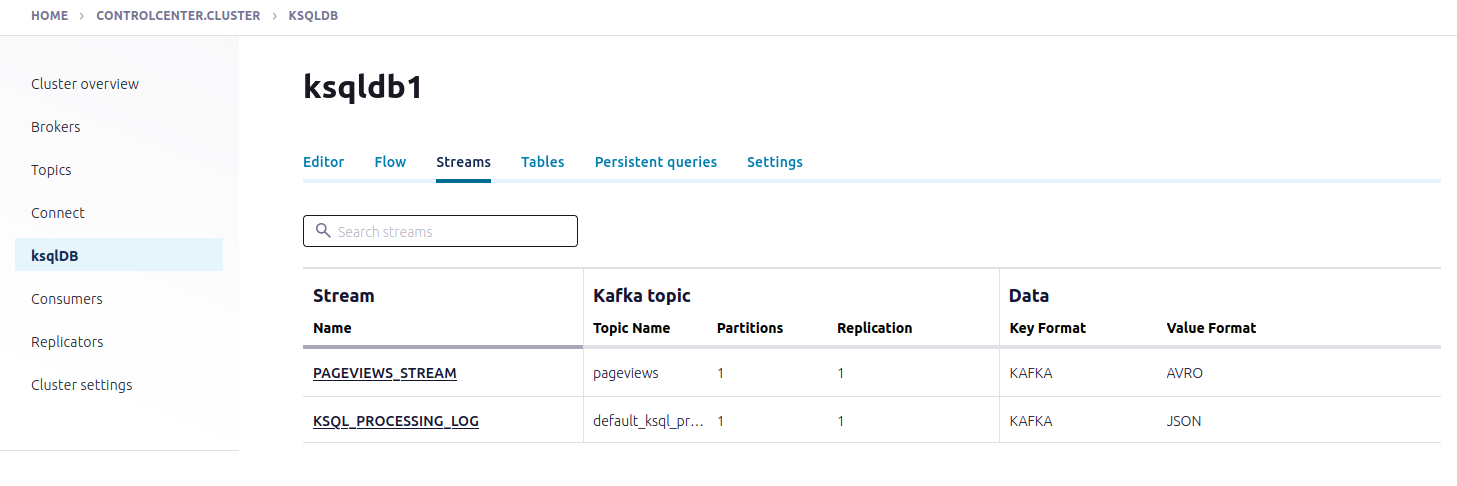
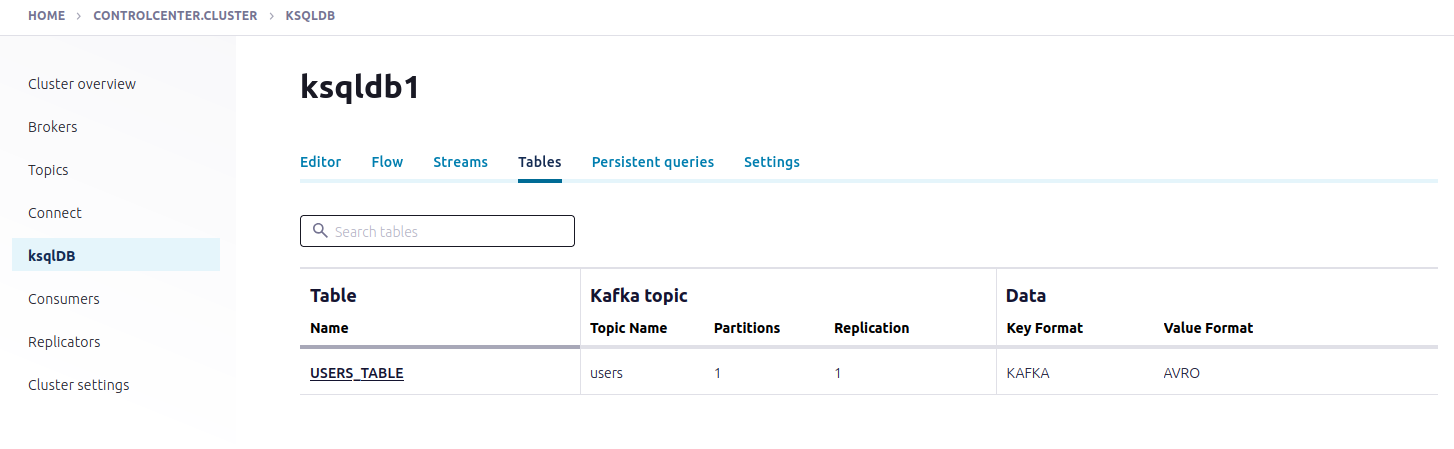
VI. Create queries to process data
- Transient query: a non-persistent, client-side query that you terminate manually or with a LIMIT clause. A transient query doesn’t create a new topic.
- Persistent query: a server-side query that outputs a new stream or table that’s backed by a new topic. It runs until you issue the TERMINATE statement. The syntax for a persistent query uses the CREATE STREAM AS SELECT or CREATE TABLE AS SELECT statements.
- Push query: A query that produces results continuously to a subscription. The syntax for a push query uses the EMIT CHANGES keyword. Push queries can be transient or persistent.
- Pull query: A query that gets a result as of “now”, like a query against a traditional relational database. A pull query runs once and returns the current state of a table. Tables are updated incrementally as new events arrive, so pull queries run with predictably low latency. Pull queries are always transient.
Query for pageviews
- Copy the following SQL into the editor and click Run query.
SELECT pageid FROM pageviews_stream EMIT CHANGES LIMIT 3;
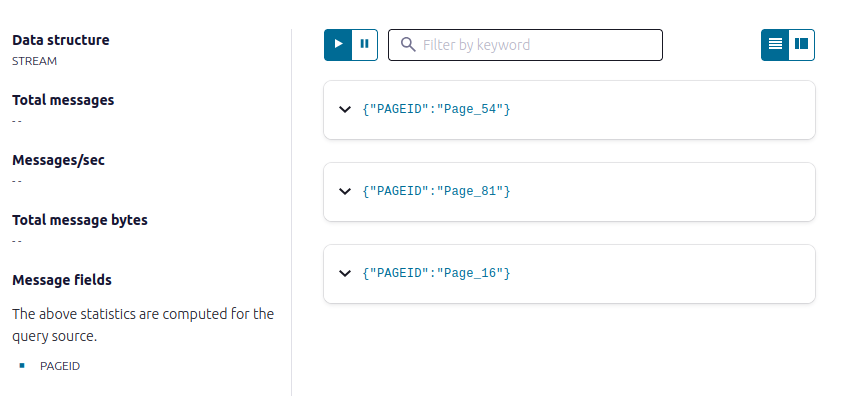
Join your stream and table
In this step, you create a stream named user_pageviews by using a persistent query that joins pageviews_stream with users_table on the userid key.
- Copy the following SQL into the editor and click Run query.
CREATE STREAM user_pageviews
AS SELECT users_table.id AS userid, pageid, regionid, gender
FROM pageviews_stream
LEFT JOIN users_table ON pageviews_stream.userid = users_table.id
EMIT CHANGES;
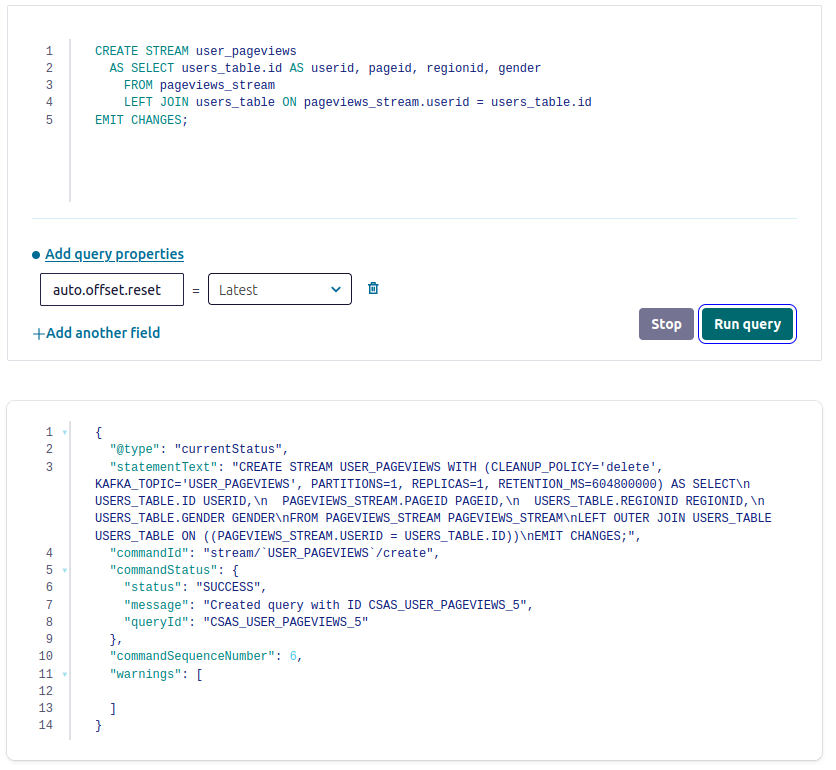
- Click Streams to open the list of streams that you can access.
- Select USER_PAGEVIEWS, and click Query stream.
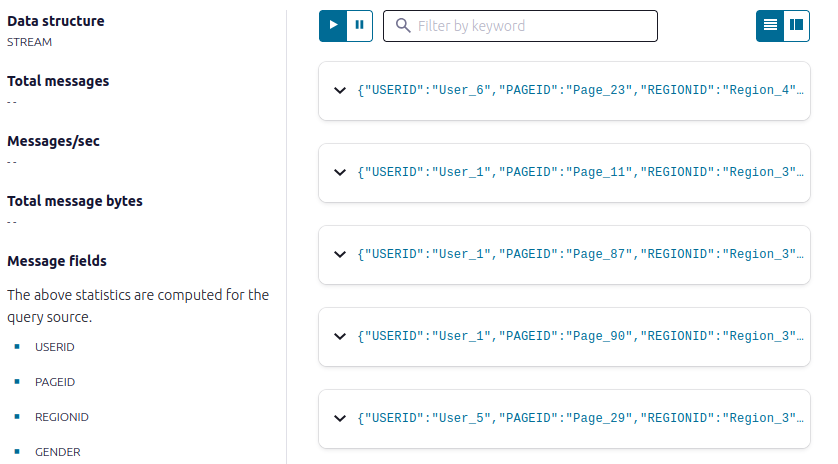
- Click Stop to end the transient push query.
Filter a stream
In this step, you create a stream, named pageviews_region_like_89, which is made of user_pageviews rows that have a regionid value that ends with 8 or 9. Results from this query are written to a new topic, named pageviews_filtered_r8_r9. The topic name is specified explicitly in the query by using the KAFKA_TOPIC keyword.
- Copy the following SQL into the editor and click Run query.
CREATE STREAM pageviews_region_like_89
WITH (KAFKA_TOPIC='pageviews_filtered_r8_r9', VALUE_FORMAT='AVRO')
AS SELECT * FROM user_pageviews
WHERE regionid LIKE '%_8' OR regionid LIKE '%_9'
EMIT CHANGES;
Your output should resemble:
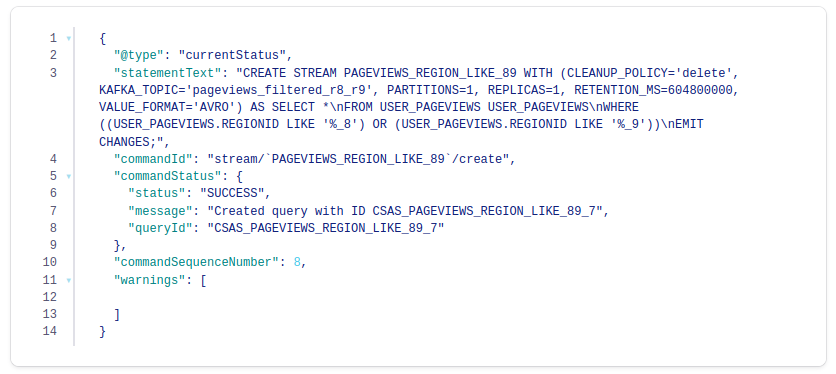
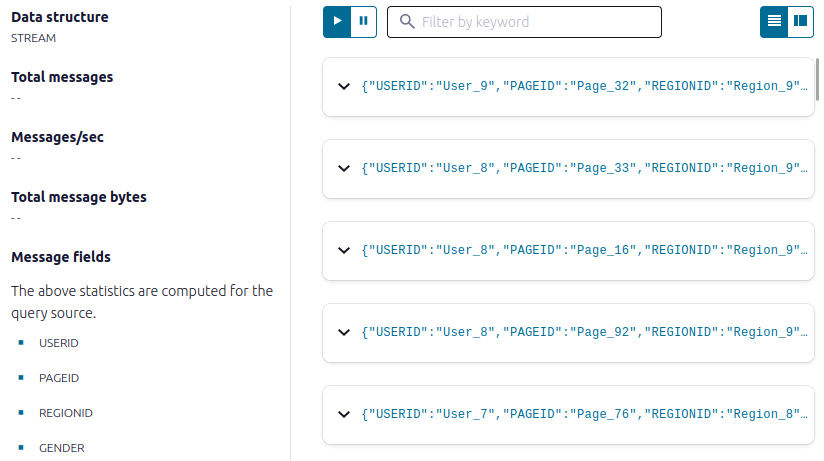
- Inspect the filtered output of the pageviews_region_like_89 stream. Copy the following SQL into the editor and click Run query.
SELECT * FROM pageviews_region_like_89 EMIT CHANGES;
Create a windowed view
In this step, you create a table named pageviews_per_region_89 that counts the number of pageviews from regions 8 and 9 in a tumbling window with a SIZE of 30 seconds. The query result is an aggregation that counts and groups rows, so the result is a table, instead of a stream.
- Copy the following SQL into the editor and click Run query.
CREATE TABLE pageviews_per_region_89 WITH (KEY_FORMAT='JSON')
AS SELECT userid, gender, regionid, COUNT(*) AS numviews
FROM pageviews_region_like_89
WINDOW TUMBLING (SIZE 30 SECOND)
GROUP BY gender, regionid, userid
HAVING COUNT(*) > 1
EMIT CHANGES;
Your output should resemble:

- Inspect the windowed output of the pageviews_per_region_89 table. Copy the following SQL into the editor and click Run query.
SELECT * FROM pageviews_per_region_89 EMIT CHANGES;
_ Click the table view button (table-view-button).
Your output should resemble:
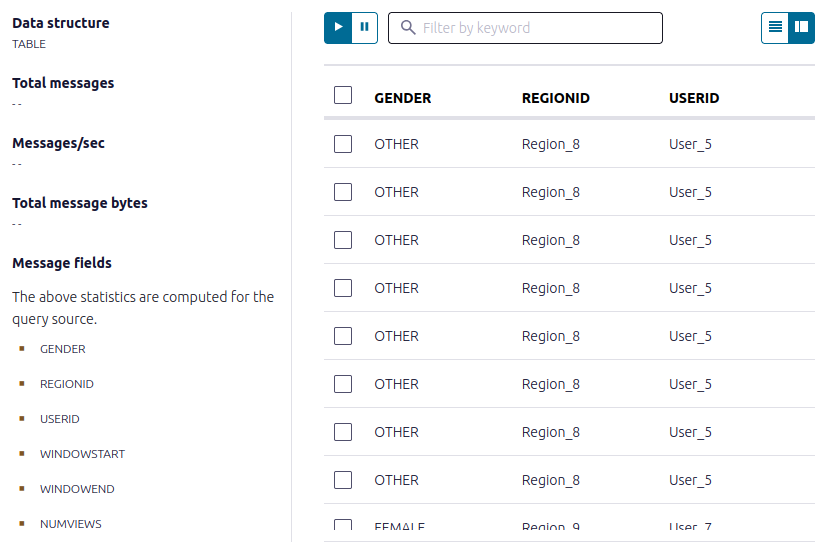
The NUMVIEWS column shows the count of views in a 30-second window.
Snapshot a table by using a pull query
You can get the current state of a table by using a pull query, which returns rows for a specific key at the time you issue the query. A pull query runs once and terminates.
In the step, you query the pageviews_per_region_89 table for all rows that have User_1 in Region_9.
Copy the following SQL into the editor and click Run query.
SELECT * FROM pageviews_per_region_89
WHERE userid = 'User_1' AND gender='FEMALE' AND regionid='Region_9';
Your output should resemble:
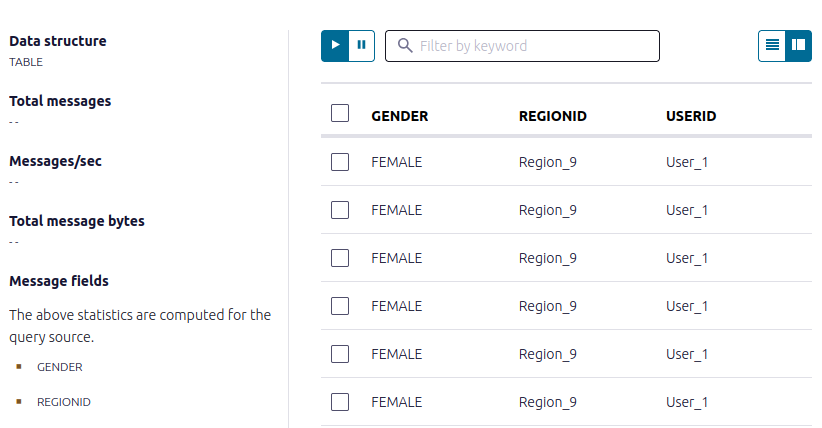
Inspect your streams and tables
All available streams and tables:
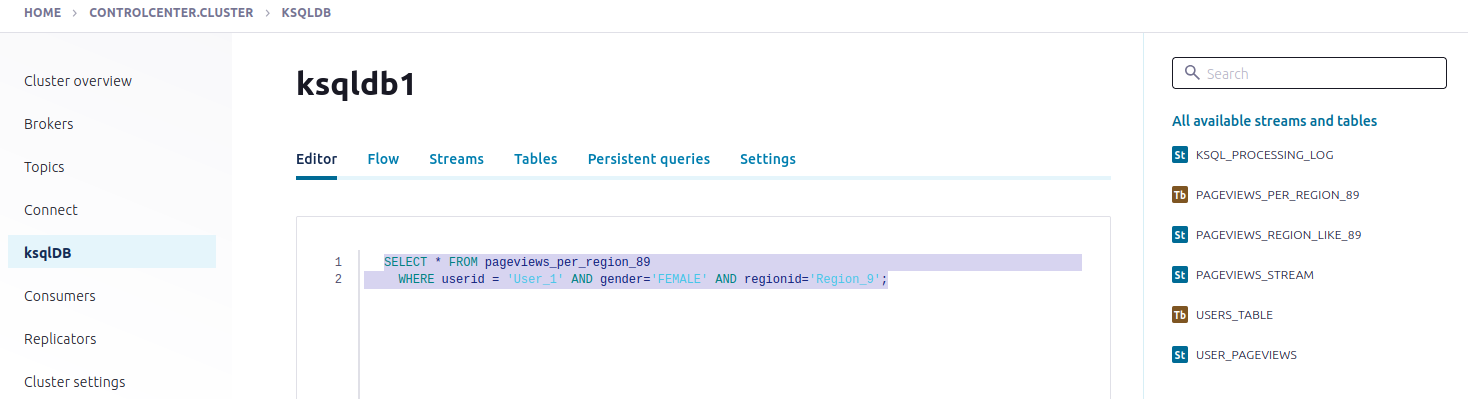
Visualize your app’s stream topology