Hive
https://hive.apache.org/
Apache Hive : Manual Installation
-
08 October 2024: EOL for release 3.x line
The Apache Hive Community has voted to declare the 3.x release line as End of Life (EOL). This means no further updates or releases will be made for this series. We urge all Hive 3.x users to upgrade to the latest versions promptly to benefit from new features and ongoing support.
-
2 October 2024: release 4.0.1 available
- As from Hive 4.x, we encourage all users to move the workload to Tez to benefit from performance gain and support.
- This release works with Hadoop 3.3.6, Tez 0.10.4.
Apache Hive is open-source data warehouse software designed to read, write, and manage large datasets extracted from the Apache Hadoop Distributed File System. It facilitates reading, writing and handling wide datasets that stored in distributed storage and queried by Structure Query Language (SQL) syntax. It provides an SQL-like interface to query and analyze large datasets stored in Hadoop’s distributed file system (HDFS) or other compatible storage systems.
Hive Architecture
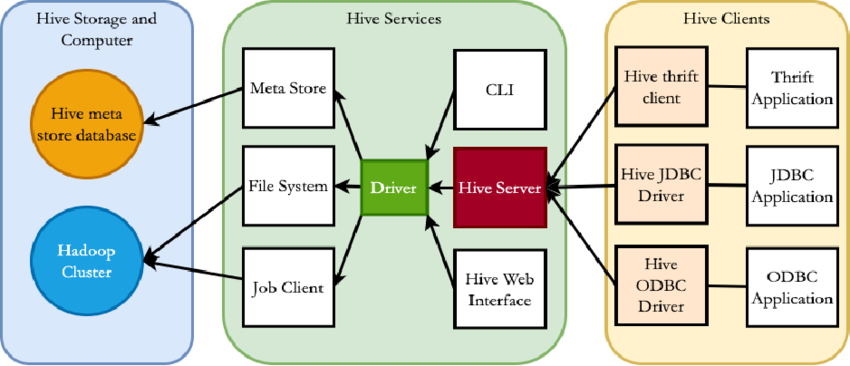
Hive Consists of Mainly 3 core parts
- Hive Clients
- Hive Services
- Hive Storage
Hive Clients
Hive allows writing applications in various languages, including Java, Python, and C++. It supports different types of clients such as:-
- Thrift Server - It is a cross-language service provider platform that serves the request from all those programming languages that supports Thrift.
- JDBC Driver - It is used to establish a connection between hive and Java applications. The JDBC Driver is present in the class org.apache.hadoop.hive.jdbc.HiveDriver.
- ODBC Driver - It allows the applications that support the ODBC protocol to connect to Hive.
Hive Services
- User Interface (UI) – As the name describes User interface provide an interface between user and hive. It enables user to submit queries and other operations to the system. Hive web UI, Hive command line, and Hive HD Insight (In windows server) are supported by the user interface.
- Hive Server – It is referred to as Apache Thrift Server. It accepts the request from different clients and provides it to Hive Driver.
- Hive CLI — The Hive CLI (Command Line Interface) is a shell where we can execute Hive queries and commands.
- Driver – Queries of the user after the interface are received by the driver within the Hive. Concept of session handles is implemented by driver. Execution and Fetching of APIs modelled on JDBC/ODBC interfaces is provided by the user.
- Metastore – All the structured data or information of the different tables and partition in the warehouse containing attributes and attributes level information are stored in the metastore. Sequences or de-sequences necessary to read and write data and the corresponding HDFS files where the data is stored. Hive selects corresponding database servers to stock the schema or Metadata of databases, tables, attributes in a table, data types of databases, and HDFS mapping.
- Hive Compiler - The purpose of the compiler is to parse the query and perform semantic analysis on the different query blocks and expressions. It converts HiveQL statements into MapReduce jobs.
- Hive Execution Engine - Optimizer generates the logical plan in the form of DAG of map-reduce tasks and HDFS tasks. In the end, the execution engine executes the incoming tasks in the order of their dependencies.
Hive Storage
Hive itself doesn't store data. Instead, it provides a schema and query engine to work with data stored in Hadoop-compatible file systems.
Data Flow in Hive
Data flow in the Hive contains the Hive and Hadoop system. Underneath the user interface, we have driver, compiler, execution engine, and metastore. All of that goes into the MapReduce and the Hadoop file system.
The data flow in the following sequence:
- We execute a query, which goes into the driver
- Then the driver asks for the plan, which refers to the query execution
- After this, the compiler gets the metadata from the metastore
- The metastore responds with the metadata
- The compiler gathers this information and sends the plan back to the driver
- Now, the driver sends the execution plan to the execution engine
- The execution engine acts as a bridge between the Hive and Hadoop to process the query
- In addition to this, the execution engine also communicates bidirectionally with the metastore to perform various operations, such as create and drop tables
- Finally, we have a bidirectional communication to fetch and send results back to the client
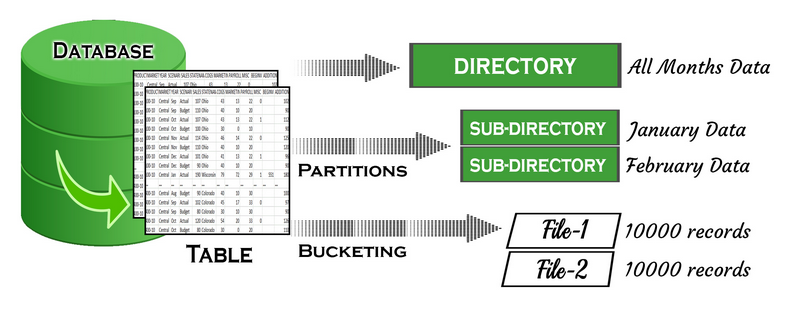
Hive Data Modeling (Data Units)
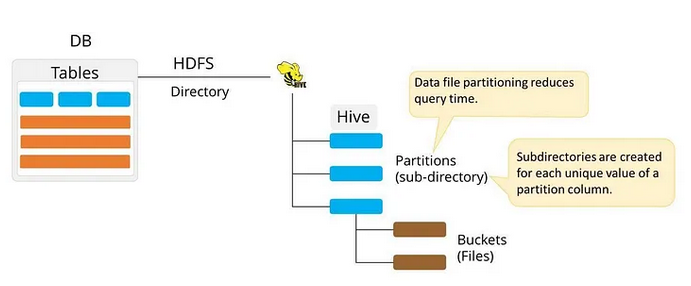
- Databases - In Hive, a database is a namespace that organizes tables and other database objects (like views, functions). It helps prevent name conflicts and manages data in a logical group.
- Syntax:
CREATE DATABASE IF NOT EXISTS my_database;USE my_database;SHOW DATABASES;
- Hive Database Storage Location:
- By default, Hive stores each database as a directory in HDFS
- [hive version path]/warehouse/my_database.db/
- Custom location:
CREATE DATABASE my_database LOCATION '/my/custom/path';
- By default, Hive stores each database as a directory in HDFS
- Syntax:
- Tables - Tables in Hive are created the same way it is done in RDBMS
- Partitions - Here, tables are organized into partitions for grouping similar types of data based on the partition key
- Buckets - Data present in partitions can be further divided into buckets for efficient querying
Hive Data Types
- Primitive Data Types:
- Numeric Data types - Data types like integral, float, decimal
- String Data type - Data types like char, string
- Date/ Time Data type - Data types like timestamp, date, interval
- Miscellaneous Data type - Data types like Boolean and binary
- Complex Data Types:
- Arrays - A collection of the same entities. The syntax is:
array<data_type> - Maps - A collection of key-value pairs and the syntax is
map<primitive_type, data_type> - Structs - A collection of complex data with comments. Syntax:
struct<col_name : data_type [COMMENT col_comment],…..> - Units - A collection of heterogeneous data types. Syntax:
uniontype<data_type, data_type,..>
- Arrays - A collection of the same entities. The syntax is:
HiveServer2
HiveServer is an optional service that allows a remote client to submit requests to Hive, using a variety of programming languages, and retrieve results. HiveServer is built on Apache ThriftTM (http://thrift.apache.org/), therefore it is sometimes called the Thrift server although this can lead to confusion because a newer service named HiveServer2 is also built on Thrift. Since the introduction of HiveServer2, HiveServer has also been called HiveServer1.
HiveServer was removed from Hive releases starting in Hive 1.0.0 (formerly called 0.14.1). Please switch over to HiveServer2.
HiveServer (HS2) supports multi-client concurrency and authentication. It is designed to provide better support for open API clients like JDBC and ODBC.
HiveServer2 Functions
- Query Execution:
- Client Interaction: Clients (like Beeline, JDBC/ODBC clients, or Hive CLI) connect to HiveServer2. Typically JDBC or ODBC. Authentication: Can include Kerberos, etc.
- Query Parsing: HiveServer2 receives a query and sends it to the Hive Compiler
- Query Planning: Plan generation: Breaks query into stages of MapReduce/Tez/Spark jobs depending on execution engine.
- Query Execution: The Execution Engine (MapReduce / Tez / Spark) runs the physical plan.
- Result Handling: HiveServer2 collects the final output:
- In-memory results for small queries.
- HDFS or temporary locations for large queries.
- Sends results back to the client over JDBC/ODBC.
- Multi-client Concurrency: Refers to the ability of Apache HiveServer2 (HS2) to handle multiple client connections and queries concurrently. This is a major improvement over the original HiveServer (now deprecated), which supported only a single client connection at a time.
- Authentication: HS2 supports several authentication methods, which are configured in hive-site.xml. Authentication Methods:
- None
- Kerberos
- LDAP
- PAM (Pluggable Authentication Modules)
- Custom (via Java Class)
- Delegation Token (used in secure environments)
- Open API Support
- HiveServer2's relation to other Hive components:
- HiveClient
- Thrift Protocol
- Apache Hadoop
- Metastore
Execution Engines
- Tez Execution Engine
(https://tez.apache.org/)
Apache Hive 4 uses Apache Tez as its default execution engine to improve query performance. - MapReduce - The original engine; converts queries to MapReduce jobs.
- Spark - Allows Hive to run on Apache Spark, providing better in-memory performance for iterative queries.
The execution engine is responsible for:
- Parsing the Query - The HiveQL query is parsed and converted into an Abstract Syntax Tree (AST).
- Physical Plan Generation
- Job Execution
🗃️ Examples
2 items