Schema Registry
Definition and Purpose
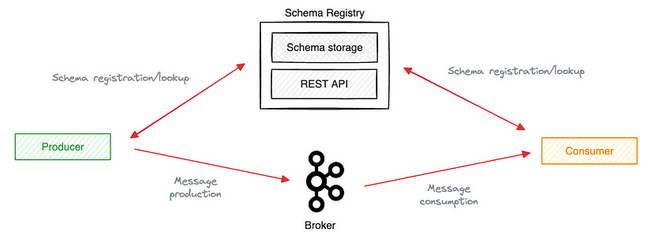
Schema Registry provides a centralized repository for managing and validating schemas for topic message data, and for serialization and deserialization of the data over the network. Producers and consumers to Kafka topics can use schemas to ensure data consistency and compatibility as schemas evolve. Schema Registry is a key component for data governance, helping to ensure data quality, adherence to standards, visibility into data lineage, audit capabilities, collaboration across teams, efficient application development protocols, and system performance.
The Kafka schema registry serves as an external application that manages data schemas. This registry resides outside the Kafka cluster. It stores, distributes, and approves schemas between producers and consumers. The primary purpose involves ensuring data reliability and consistency. By maintaining a central repository for schemas, the registry facilitates seamless data serialization and deserialization.
Key Features
- Centralized Schema Storage: Maintains a single source of truth for all schemas.
- Schema Versioning: Tracks changes by creating new versions for each schema update.
- Compatibility Checks: Ensures new schemas remain compatible with existing ones.
- RESTful Interface: Provides a user-friendly API for schema management.
- Support for Multiple Formats: Handles Avro, JSON Schema, and Protobuf formats.
Schema Types
Avro
Introduction
Apache Avro™ is a data serialization system.
Avro provides:
- Rich data structures.
- A compact, fast, binary data format.
- A container file, to store persistent data.
- Remote procedure call (RPC).
- Simple integration with dynamic languages. Code generation is not required to read or write data files nor to use or implement RPC protocols. Code generation as an optional optimization, only worth implementing for statically typed languages.
Schemas
Avro relies on schemas. When Avro data is read, the schema used when writing it is always present. This permits each datum to be written with no per-value overheads, making serialization both fast and small. This also facilitates use with dynamic, scripting languages, since data, together with its schema, is fully self-describing.
When Avro data is stored in a file, its schema is stored with it, so that files may be processed later by any program. If the program reading the data expects a different schema this can be easily resolved, since both schemas are present.
When Avro is used in RPC, the client and server exchange schemas in the connection handshake. (This can be optimized so that, for most calls, no schemas are actually transmitted.) Since both client and server both have the other’s full schema, correspondence between same named fields, missing fields, extra fields, etc. can all be easily resolved.
Avro schemas are defined with JSON . This facilitates implementation in languages that already have JSON libraries.
Protobuf
Protocol Buffers are language-neutral, platform-neutral extensible mechanisms for serializing structured data.a
It’s like JSON, except it’s smaller and faster, and it generates native language bindings. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
Protocol buffers are a combination of the definition language (created in .proto files), the code that the proto compiler generates to interface with data, language-specific runtime libraries, the serialization format for data that is written to a file (or sent across a network connection), and the serialized data.
JSON Schema
Comprehensive Guide to Kafka Schema Registry
Manage Schemas in Confluent Platform
Review the step-by-step tutorial for using Schema Registry
Schema Registry Documentation
Tutorial: Use Schema Registry on Confluent Platform to Implement Schemas for a Client Application
Sending Protobuf message using custom schema in Kafka stream
How to Use Protobuf With Apache Kafka and Schema Registry
Kafka consumer
Kafka consumer (github)
Guide to Apache Avro and Kafka
Guide to Apache Avro and Kafka (github)
kafka-protobuf
kafka-protobuf (github)
https://developer.confluent.io/confluent-tutorials/console-consumer-producer-avro/
Encode/Decode Avro Messages
Kafka programming in Java with Avro serialization
Implementing a basic Kafka Producer and Consumer using Spring Boot, Spring Kafka and Avro schema
Implementing a basic Kafka Producer and Consumer using Spring Boot, Spring Kafka and Avro schema (github)