MapReduce: the First Program
Start Hadoop: Single Node Cluster
Based on https://www.h2kinfosys.com/blog/hadoop-mapreduce-examples/
Description
MapReduce: Word Counter:
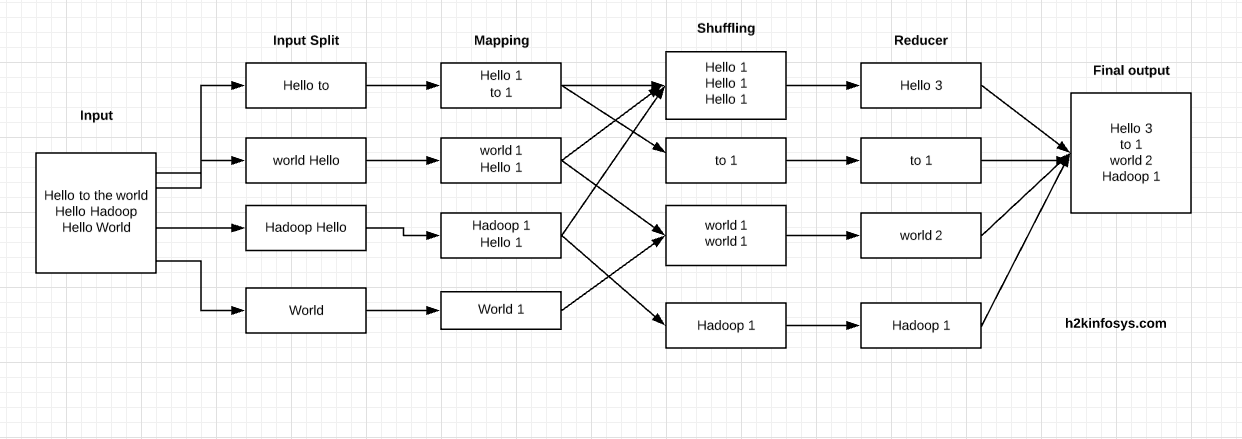
We'll implement the above.
Prerequisites
- Linux
- JDK 11
- Maven
- Hadoop 3.4.1
Start Programming
su - hadoop
start-dfs.sh
start-yarn.sh
Create wordcount/input in /home/hadoop
mkdir wordcount
mkdir wordcount/input
chmod -R 777 /home/hadoop/wordcount
Create two input files (local)
in wordcount/input
input_one with content:
Hello to the World
and
input_two with content:
Hello Hadoop Hello World
Create HDFS input folder:
hdfs dfs -mkdir /wordcount
hdfs dfs -mkdir /wordcount/input
Copy local files to HDFS file system
hdfs dfs -copyFromLocal /home/hadoop/wordcount/input/input_one /wordcount/input/
hdfs dfs -copyFromLocal /home/hadoop/wordcount/input/input_two /wordcount/input/
Check if both files have been copied
hdfs dfs -ls /wordcount/input/
hadoop@LL01:~/hadoop-3.4.1/bin$ ./hdfs dfs -ls /wordcount/input/
Found 2 items
-rw-r--r-- 1 hadoop supergroup 19 2025-03-11 11:00 /wordcount/input/input_one
-rw-r--r-- 1 hadoop supergroup 25 2025-03-11 11:04 /wordcount/input/input_two
Java Program
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>mapreduce-first-program</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<target.java.version>11</target.java.version>
<maven.compiler.source>${target.java.version}</maven.compiler.source>
<maven.compiler.target>${target.java.version}</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.4.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${target.java.version}</source>
<target>${target.java.version}</target>
</configuration>
</plugin>
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
<!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:flink-shaded-force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>org.apache.logging.log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>WordCount.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Map.java
package WordCount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException
{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens())
{
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
WordCount.java
package WordCount;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount
{
public static void main(String[] args) throws Exception
{
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
Reduce.java
package WordCount;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable>
{
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException
{
int sum = 0;
while (values.hasNext())
{
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
Run
mvn clean package
Copy
mapreduce-first-program-1.0-SNAPSHOT.jar
to
/home/hadoop/wordcount/ .
Run the MapReduce using the command given below.
hadoop jar /home/hadoop/wordcount/mapreduce-first-program-1.0-SNAPSHOT.jar /wordcount/input /wordcount/output
Output:
./hadoop jar /home/hadoop/wordcount/mapreduce-first-program-1.0-SNAPSHOT.jar /wordcount/input /wordcount/output
2025-03-11 13:11:54,545 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /127.0.0.1:8032
2025-03-11 13:11:54,616 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /127.0.0.1:8032
...
...
Peak Map Physical memory (bytes)=375726080
Peak Map Virtual memory (bytes)=2788450304
Peak Reduce Physical memory (bytes)=260698112
Peak Reduce Virtual memory (bytes)=2783264768
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=47
File Output Format Counters
Bytes Written=36
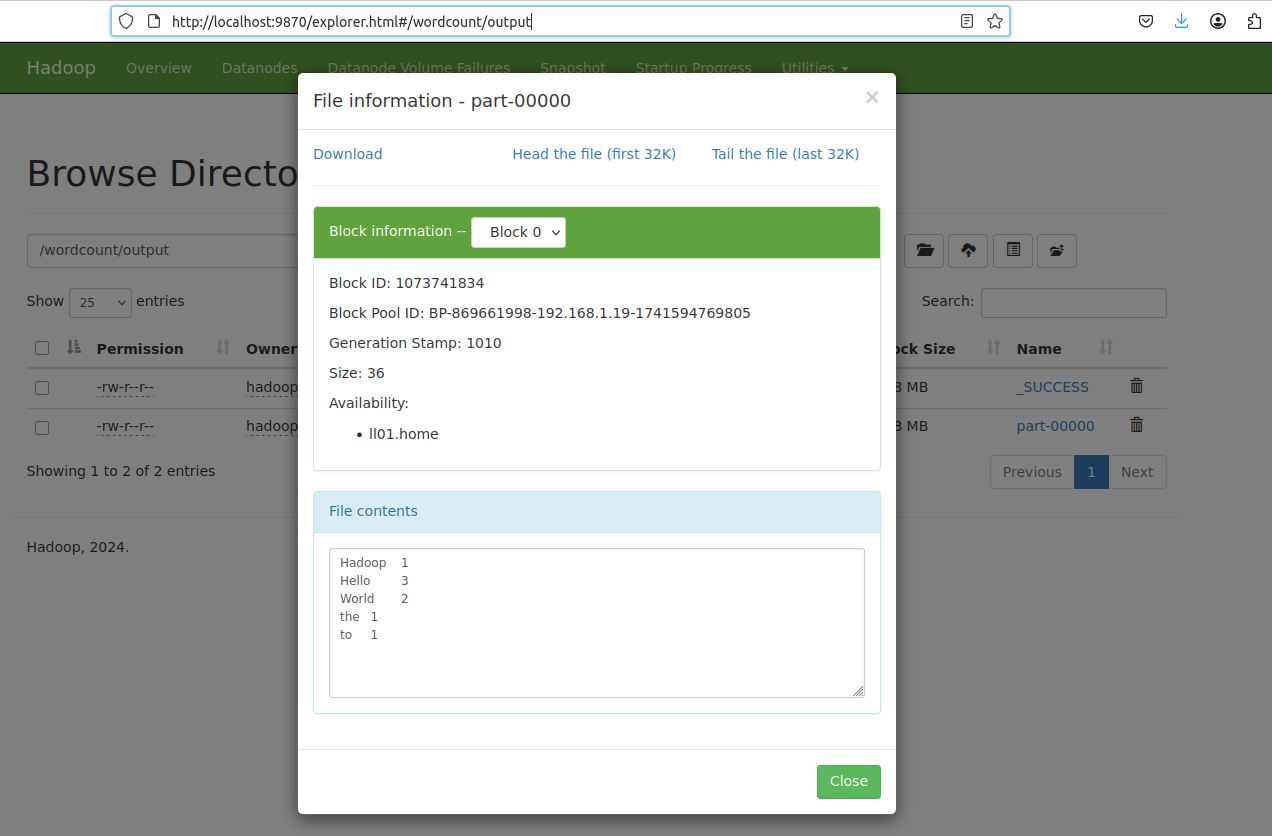
hadoop dfs -cat /wordcount/output/part-00000
Output:
Hadoop 1
Hello 3
World 2
the 1
to 1
or
http://localhost:9870
Source of the java program:
https://github.com/ZbCiok/zjc-examples/tree/main/streams/hadoop/mapreduce-first-program