MapReduce: Matrix-Vector Multiplication
Description
Calculate the product of a matrix M (assumed sparse) and a vector v:
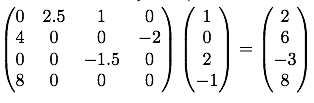
Workflow - 2 MapReduce jobs
-
CellMultiplication: Mapper1 + Mapper2 ---> Reducer Mapper1: read the non-zero elements in the matrix file
(row, col, M[row][col])input:<offset, line>output:<col, row=M[row][col]>Mapper2: read the vector input:<offset, line>output:<row, v[row]>Reducer: multiply a matrix column with the corresponding vector row input:<col, (row1=M[row1][col], row2=M[row2][col], ..., v[col])>output:<row, M[row][col]*v[col]> -
CellSum: Mapper ---> Reducer
Mapper: read the intermediate result of cell multiplication input:
<offset, line>output:<row, M[row][col]*v[col]>Reducer: sum up all the cell product to the final value for each vector row input:
<row, (M[row][col1]*v[col1], M[row][col2]*v[col2], ...)>output:<row, M[row][col1]*v[col1] + M[row][col2]*v[col2] + ...>
Prerequisites
- Linux
- JDK 11
- Maven
- Hadoop 3.4.1
HDFS
Create files in HDFS
su - hadoop
start-dfs.sh
start-yarn.sh
Create local files:
/home/hadoop/examples/MatrixVectorMultiplication/input/matrix/matrix.txt
/home/hadoop/examples/MatrixVectorMultiplication/input/vector/vector.txt
matrix.txt and vector.txt see Java Program
Copy the above files to HDFS:
hdfs dfs -copyFromLocal /home/hadoop/examples/MatrixVectorMultiplication/input/matrix /examples/MatrixVectorMultiplication/input/matrix
hdfs dfs -copyFromLocal /home/hadoop/examples/MatrixVectorMultiplication/input/vector /examples/MatrixVectorMultiplication/input/vector
Check if both files have been copied:
hdfs dfs -ls /examples/MatrixVectorMultiplication/input
Output:
./hdfs dfs -ls /examples/MatrixVectorMultiplication/input
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2025-03-14 09:21 /examples/MatrixVectorMultiplication/input/matrix
drwxr-xr-x - hadoop supergroup 0 2025-03-14 09:22 /examples/MatrixVectorMultiplication/input/vector
Java Program
Program Structure
.
├── dependency-reduced-pom.xml
├── input
│ ├── matrix
│ │ └── matrix.txt
│ └── vector
│ └── vector.txt
├── pom.xml
├── README.md
├── src
│ └── main
│ └── java
│ ├── CellMultiplication.java
│ ├── CellSum.java
│ └── Driver.java
└── toy_example.png
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>MatrixVectorMultiplication</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<target.java.version>11</target.java.version>
<maven.compiler.source>${target.java.version}</maven.compiler.source>
<maven.compiler.target>${target.java.version}</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.4.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${target.java.version}</source>
<target>${target.java.version}</target>
</configuration>
</plugin>
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
<!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:flink-shaded-force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>org.apache.logging.log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>Driver</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Driver.java
public class Driver {
public static void main(String[] args) throws Exception {
CellMultiplication multiplication = new CellMultiplication();
CellSum sum = new CellSum();
// parse args
String matrixInputPath = args[0];
String vectorInputPath = args[1];
String subSumOutputPath = args[2];
String sumOutputPath = args[3];
// run the first job
String[] cellMultiplicationArgs = {matrixInputPath, vectorInputPath, subSumOutputPath};
multiplication.main(cellMultiplicationArgs);
// run the second job
String[] cellSumArgs = {subSumOutputPath, sumOutputPath};
sum.main(cellSumArgs);
}
}
CellMultiplication.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class CellMultiplication extends Configured implements Tool {
public static class MatrixReaderMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// input: <offset, line>, each line is: row col element
// output: <col, row=element>
String[] cell = value.toString().trim().split("\t");
String col = cell[1];
String rowVal = cell[0] + "=" + cell[2];
context.write(new Text(col), new Text(rowVal));
}
}
public static class VectorReaderMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// input: <offset, line>, each line is: row element
// output: <row, element>
String[] cell = value.toString().trim().split("\t");
context.write(new Text(cell[0]), new Text(cell[1]));
}
}
public static class CellReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// input: <col, row1=element1, row2=element2, ..., v>
// output: <row, element * v>
double vecCell = 0.0;
List<String> matrixRow = new ArrayList<String>();
for (Text value : values) {
String val = value.toString();
if (val.contains("=")) {
matrixRow.add(val);
} else {
vecCell = Double.parseDouble(val);
}
}
for (String rowVal : matrixRow) {
String row = rowVal.split("=")[0];
double value = Double.parseDouble(rowVal.split("=")[1]) * vecCell;
context.write(new Text(row), new Text(String.valueOf(value)));
}
}
}
public int run(String[] args) throws Exception {
if (args.length != 3) {
System.err.printf("Usage: %s [generic options] <input> <output>\n", getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Cell Multiplication");
job.setJarByClass(CellMultiplication.class);
job.setReducerClass(CellReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// Multiple input paths: one for each Mapper
// No need to use job.setMapperClass()
MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class, MatrixReaderMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class, VectorReaderMapper.class);
FileOutputFormat.setOutputPath(job, new Path(args[2]));
return job.waitForCompletion(true)? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new CellMultiplication(), args);
if (exitCode == 1) {
System.exit(exitCode);
}
}
}
CellSum.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.text.DecimalFormat;
public class CellSum extends Configured implements Tool {
public static class SumMapper extends Mapper<LongWritable, Text, Text, DoubleWritable> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// input: <offset, line>, each line is: row subSum
// output: <row, subSum>
String[] cell = value.toString().trim().split("\t");
double subSum = Double.parseDouble(cell[1]);
context.write(new Text(cell[0]), new DoubleWritable(subSum));
}
}
public static class SumReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> {
@Override
public void reduce(Text key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException {
// input: <row, (subSum1, subSum2, ...)>
// output: <row, subSum1+subSum2+...>
double sum = 0.0;
for (DoubleWritable subSum : values) {
sum += subSum.get();
}
DecimalFormat df = new DecimalFormat("#.0000");
sum = Double.valueOf(df.format(sum));
context.write(key, new DoubleWritable(sum));
}
}
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.err.printf("Usage: %s [generic options] <input> <output>\n", getClass().getSimpleName());
ToolRunner.printGenericCommandUsage(System.err);
return -1;
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Cell Sum");
job.setJarByClass(CellSum.class);
job.setMapperClass(SumMapper.class);
job.setReducerClass(SumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true)? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new CellSum(), args);
if (exitCode == 1) {
System.exit(exitCode);
}
}
}
Run
mvn clean package
hadoop jar /home/hadoop/examples/MatrixVectorMultiplication/MatrixVectorMultiplication-1.0-SNAPSHOT.jar /examples/MatrixVectorMultiplication/input/matrix/matrix/ /examples/MatrixVectorMultiplication/input/vector/vector/ /examples/MatrixVectorMultiplication/output/sub /examples/MatrixVectorMultiplication/output/sum
Verify
Sub:
hdfs dfs -ls /examples/MatrixVectorMultiplication/output/sub
Output:
-rw-r--r-- 1 hadoop supergroup 0 2025-03-14 12:02 /examples/MatrixVectorMultiplication/output/sub/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 37 2025-03-14 12:02 /examples/MatrixVectorMultiplication/output/sub/part-r-00000
Sum:
hdfs dfs -ls /examples/MatrixVectorMultiplication/output/sum
Output:
-rw-r--r-- 1 hadoop supergroup 0 2025-03-14 12:02 /examples/MatrixVectorMultiplication/output/sum/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 25 2025-03-14 12:02 /examples/MatrixVectorMultiplication/output/sum/part-r-00000
Content:
Sub:
hdfs dfs -cat /examples/MatrixVectorMultiplication/output/sub/part-r-00000
Output:
4 8.0
2 4.0
1 0.0
3 -3.0
1 2.0
2 2.0
Sum:
hdfs dfs -cat /examples/MatrixVectorMultiplication/output/sum/part-r-00000
Output:
1 2.0
2 6.0
3 -3.0
4 8.0
Source of the java program:
https://github.com/ZbCiok/zjc-examples/tree/main/streams/hadoop/MatrixVectorMultiplication